Causal inference is about more than finding patterns in data — it’s about understanding what causes what.
It asks the fundamental question: “If we change one thing, what happens to another?”
To answer this, we build scientific models that explain relationships between variables using logic and theory.
Why Start with the Scientific Model?
If our understanding of how things are connected is wrong, no statistical method can fix it.
Good causal inference requires:
Domain knowledge
Theoretical understanding
Careful thinking about relationships
Statistical tools can only answer the questions we pose correctly.
Correlation Does Not Imply Causation
An Example: Countries with faster internet speeds (X) have stronger economies (Y). But, correlation is likely spurious because wealthier countries are more likely to invest in advanced infrastructure, including high-speed internet. Economic strength and internet speed are both outcomes of higher national wealth.
But Also, Causation Does Not Imply Correlation
An Example: When cruise control is set on a car, changes in road incline (X) causally affect the engine’s power output (Z) to maintain the set speed (Y). Despite the causal effect of road incline on engine power, the vehicle speed Y remains constant due to the cruise control. Data collected on vehicle speed (Y) and road incline (X) will show no correlation, despite X causing Y. The cruise control is an example of a feedback control mechanism.
Potential Outcomes Framework
Last week, you made a decision to either:
Read the Module 18 material (\(x_i = 1\))
Not read the Module 18 material (\(x_i = 0\))
Which of these actions will be better for your comprehension of today’s lecture?
Definition of Variables
We’ll label the treatment/exposure, reading the material, as \(x_i\).
We’ll label the outcome, comprehension of the lecture, as \(y_i\).
The Potential Outcomes
We have two potential outcomes in this scenario:
One represents your comprehension if you read the material: \(y_i(1)\)
The other represents your comprehension if you didn’t read the material: \(y_i(0)\)
If you read the Module 18 material prior to class:
We observe \(y_i(1)\)
The outcome \(y_i(0)\) remains the counterfactual (unobserved)
If you didn’t read the Module 18 material prior to class:
We observe \(y_i(0)\)
The outcome \(y_i(1)\) remains the counterfactual (unobserved)
The Individual-Level Causal Effect
The individual‐level causal effect is: \[y_i(1) - y_i(0)\]
That is — the difference in your comprehension of the lecture if you read the Module 18 material versus if you didn’t read the material.
This difference is unknowable!
This is the fundamental problem of causal inference (Holland, 1986).
Random Assignment to Condition
Let’s imagine that I randomly assign half of you to read the Module 18 material and the other half to not read the material.
If you’re assigned to read the material, and you read it — then we observe \(y_i(1)\).
If you’re not assigned to read the material, and you don’t read it — then we observe \(y_i(0)\).
Therefore, we can compute the Average Causal Effect as:
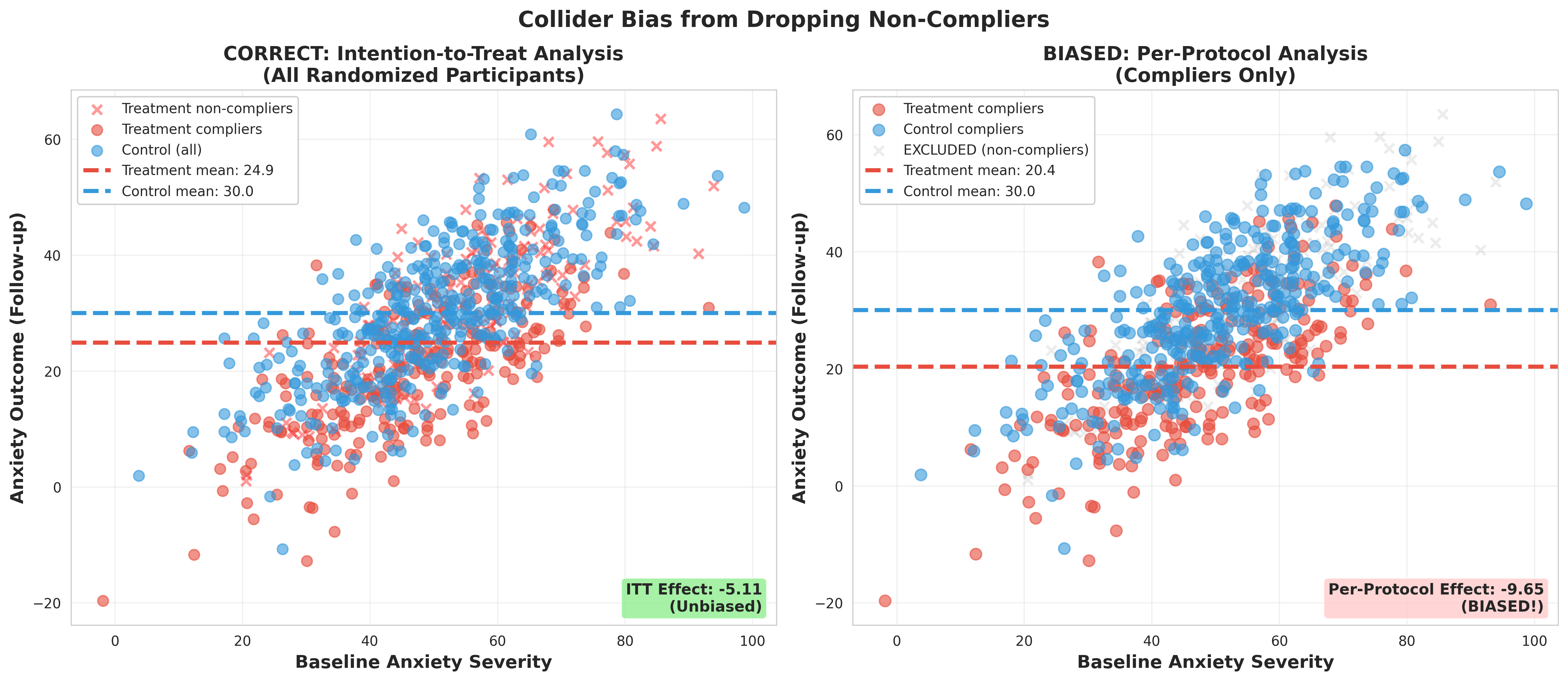
Drop-out: Participants fail to provide outcome data
Unmanipulable causes: Some causes cannot be directly manipulated (e.g., emotional responses)
Ethical and practical constraints: Randomization might be unethical (e.g., drug use) or unfeasible (e.g., socioeconomic status)
Roadmap: When Perfect Experiments Aren’t Possible
Today we’ll learn about tools for causal inference:
Directed Acyclic Graphs (DAGs) — Visual models of causal relationships
Three Key Structures — Forks, Pipes, and Colliders
Identification Strategy — How to determine what variables to control for
What Can Go Wrong — Why controlling for the wrong variables can bias results
What to Do Absent a Perfectly Executed Experiment?
In these scenarios, it’s helpful to think about the entire causal network underlying the data. Graphical notation can make it easier to understand and analyze these complex relationships.
Directed Acyclic Graphs (DAGS)
DAGS are a powerful and intuitive tool for representing causal relationships.
Heuristic Models: DAGs are simplified representations of a causal model, focusing on the structure of relationships rather than exact mechanisms or mathematical details.
Directed: Each arrow shows the direction of influence between two variables. An arrow from X → Y means X is assumed to cause Y (but not the other way around).
Acyclic: DAGs do not allow loops or cycles—no variable can directly or indirectly cause itself. This ensures clarity in identifying causal pathways.
Anonymous Influence: DAGs don’t specify how variables influence each other (e.g., linear or nonlinear effects); they only indicate that one variable influences another.
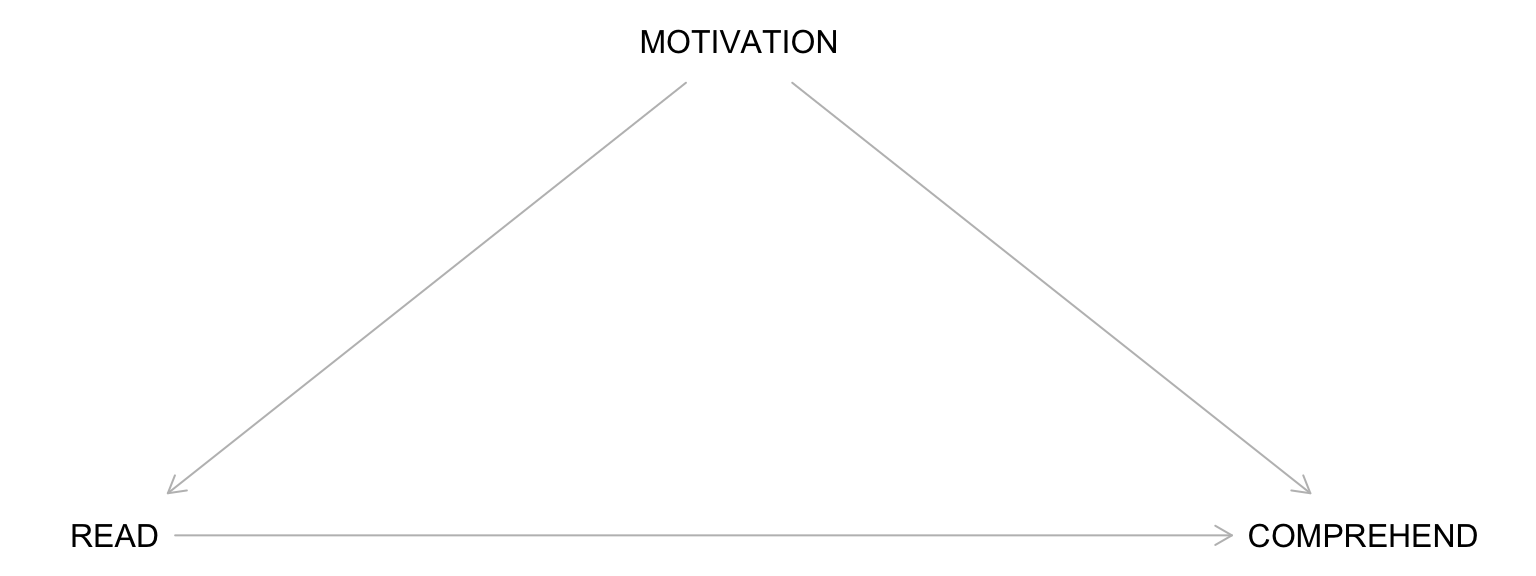
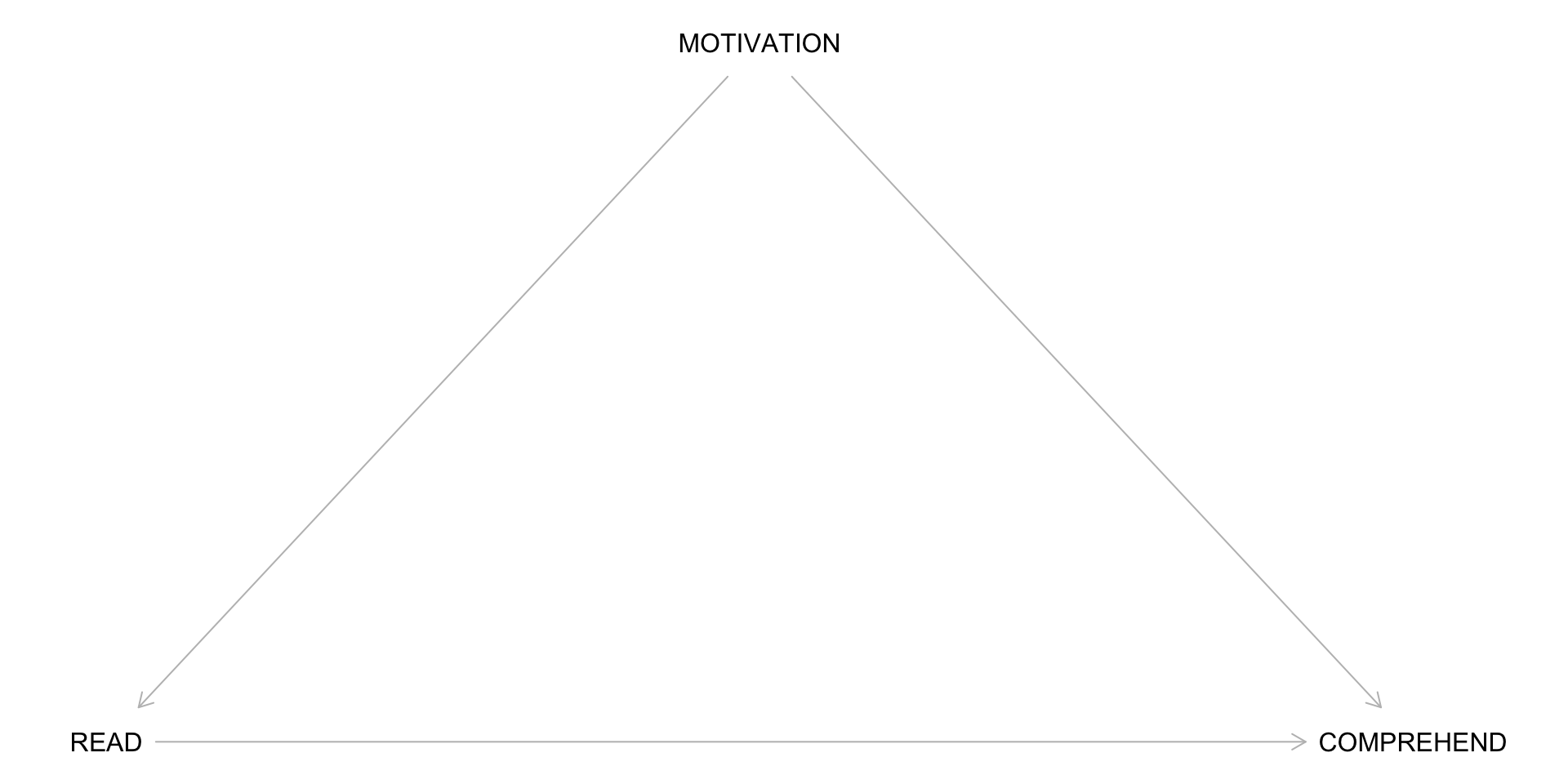
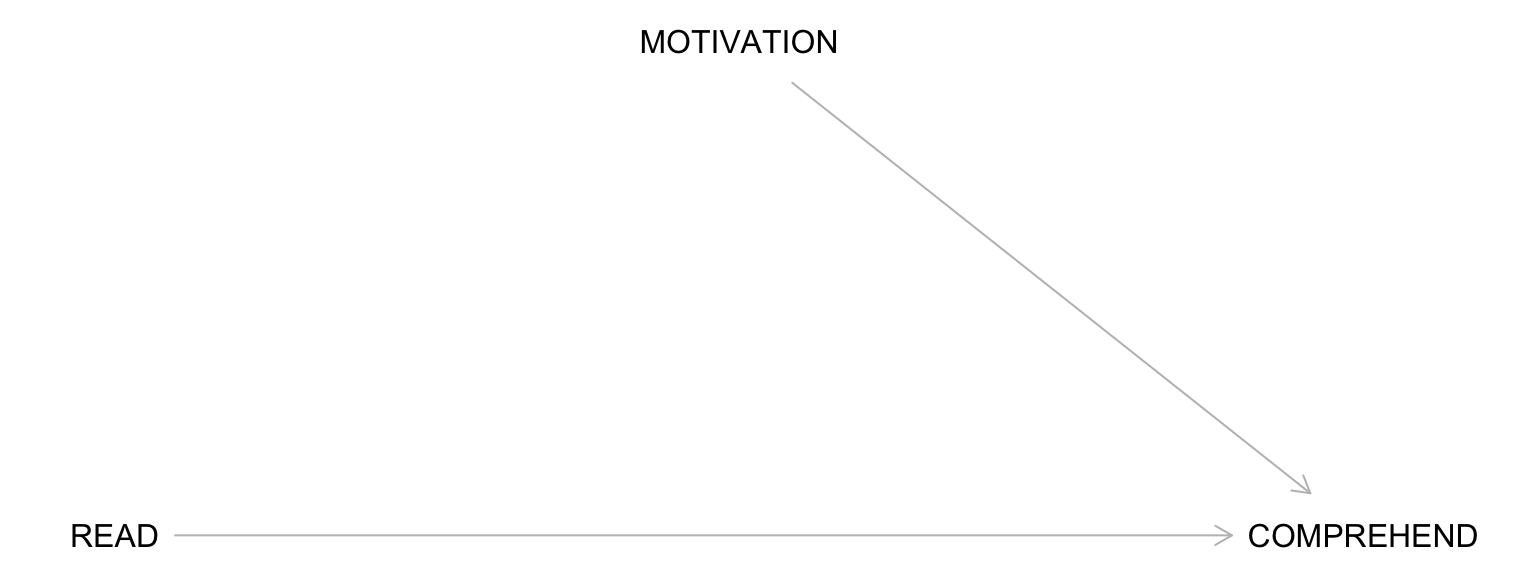
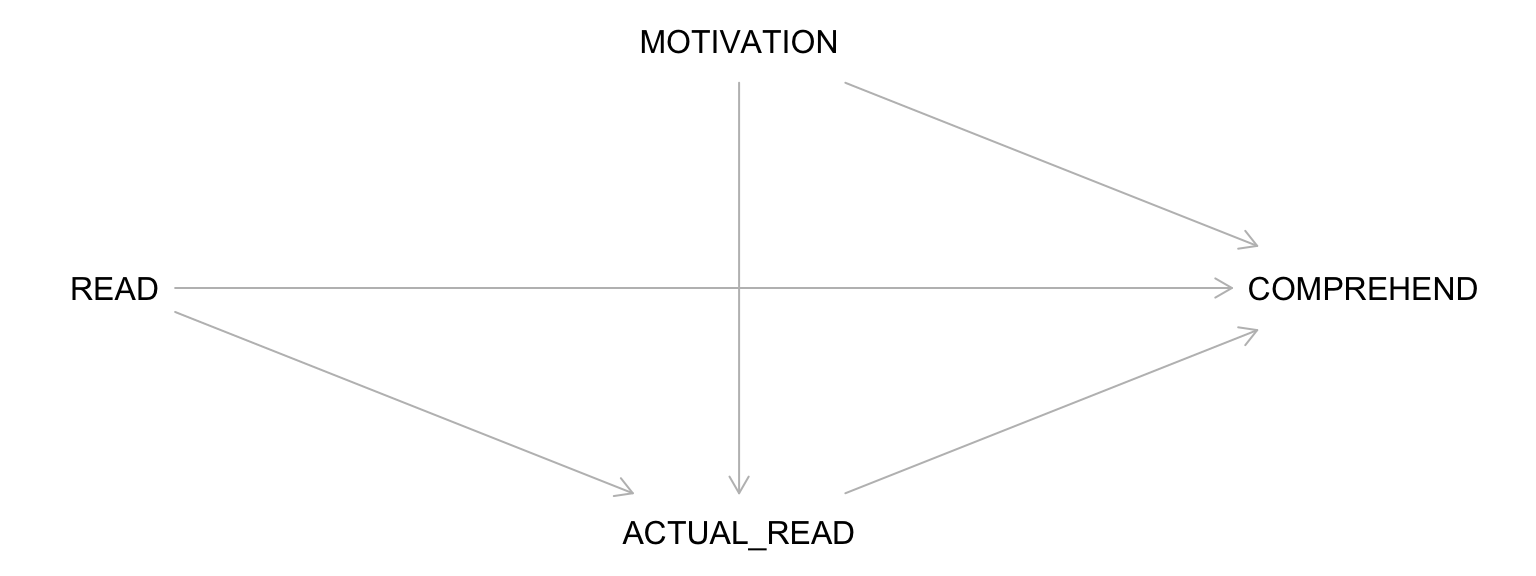
An Example DAG
Start by drawing the exposure (e.g., reading the material) and the outcome (e.g., comprehension of the lecture).
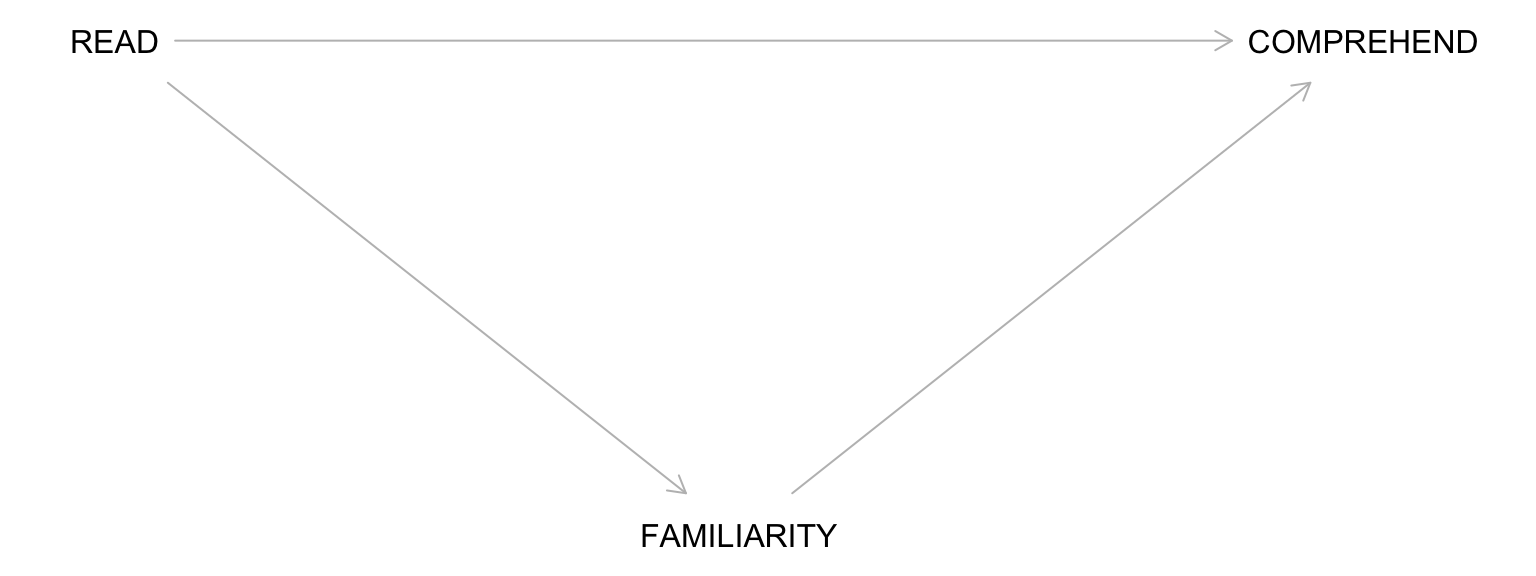
Building a Complete DAG: Step 1
Draw all common causes of X and Y – including measured and unmeasured variables.
Common causes create confounding
Omitting them means assuming they don’t exist
Both observed and unobserved confounders should be represented
Building a Complete DAG: Step 2
As you add new variables, include any common causes of any pair of variables in your DAG.
This ensures that the DAG accounts for potential bias introduced by shared causes
Keep building until you’ve represented all confounding relationships
If there are variables through which X affects Y (i.e., mediators):
Draw arrows from X to the mediator(s)
Draw arrows from the mediator(s) to Y
Building a Complete DAG: Step 3
Include all selection variables – these represent selection processes that occur as part of the study:
Drop out
Death
Non-compliance
Sample selection
Critical Assumption
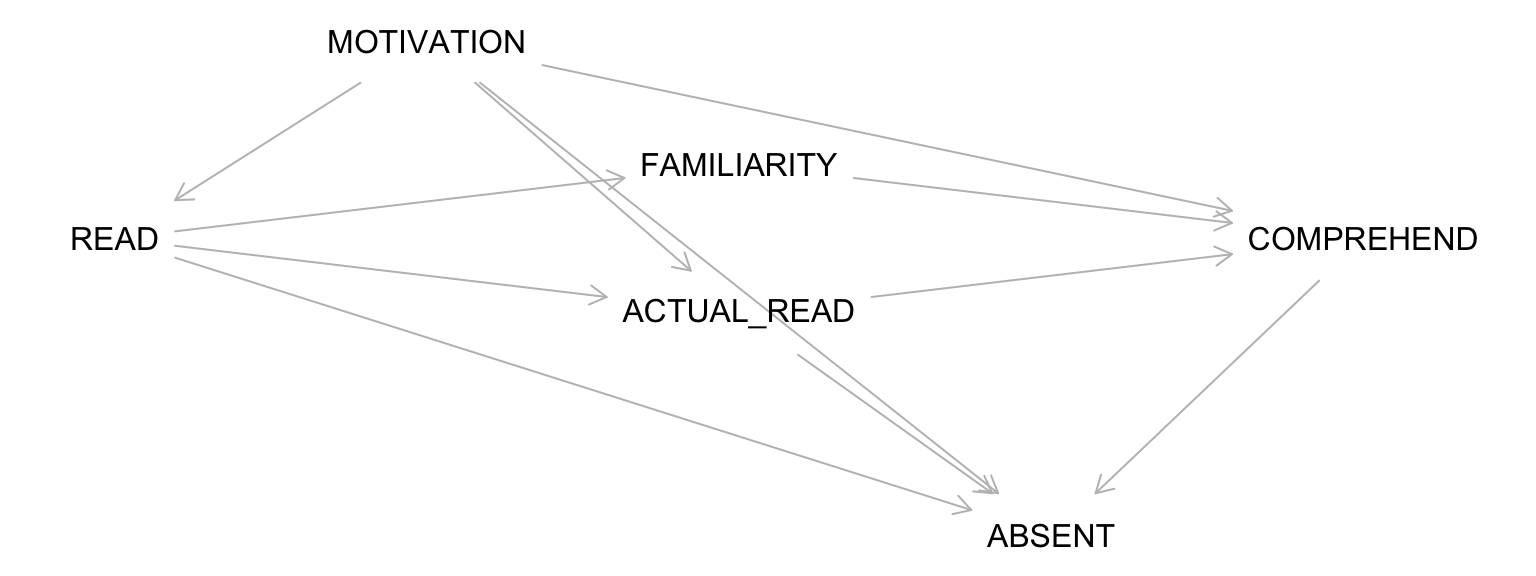
Drawing a DAG requires expert knowledge and must be complete! NOT including an arrow implies an ASSUMPTION that there is NO CAUSAL EFFECT.
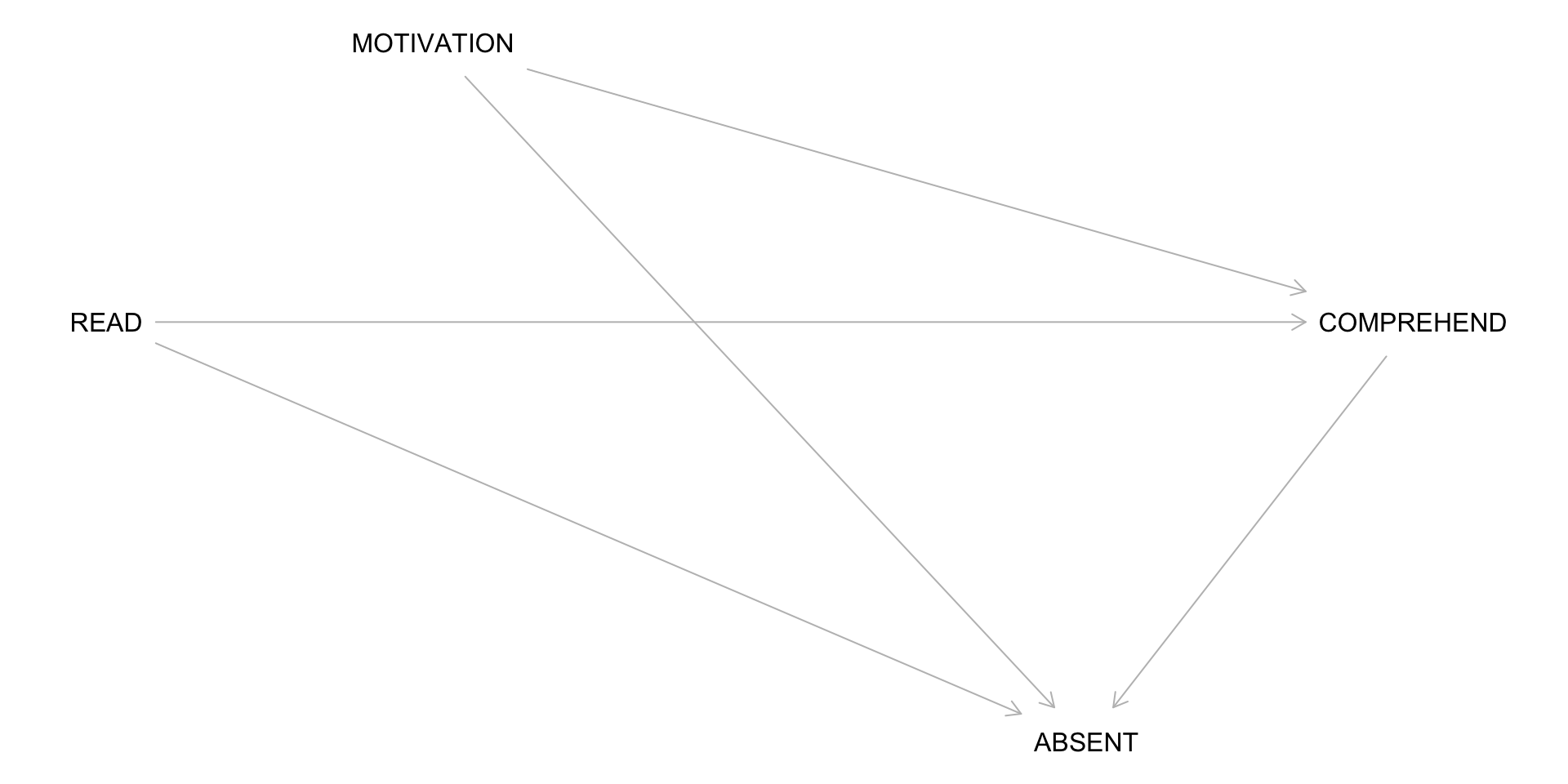
Consider an Observational Version of the Study
For the READ to COMPREHENSION example, let’s imagine I simply assessed whether students chose to read the material:
Will the difference in comprehension between those who chose to read vs. not read represent an average causal effect?
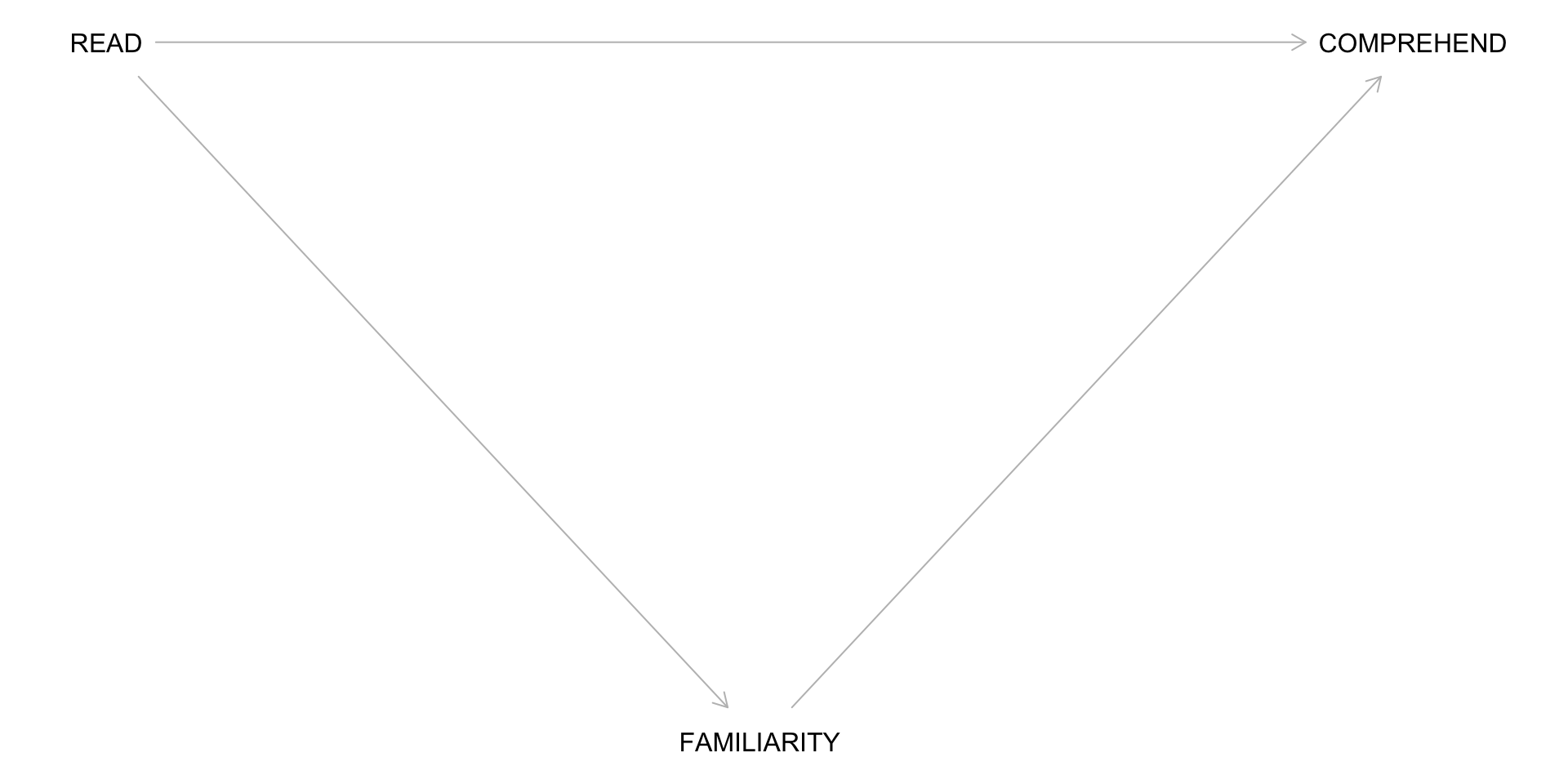
A DAG for the Observational Study
Understanding Paths in DAGs
Path: A sequence of arrows between two variables in a DAG, not passing through any variable more than once. The direction of the arrows is irrelevant when defining a path.
Causal Paths: All arrows point in the same direction, from cause (X) to effect (Y). This path represents a direct or indirect causal relationship.
Non-Causal Paths: Include at least one arrow that points toward X (or away from Y). These paths may introduce confounding or other non-causal associations.
Simply estimate the overall effect of READ → COMPREHEND
Otherwise, you will “explain away” part of the effect of interest
If You Want the Direct Effect:
You can adjust for the mediator, but interpretation of the exposure takes extra care
This is the domain of mediation analysis
Generate Data
What do you Predict?
Before running the code, make a prediction:
What will happen to the coefficient on X when we:
Don’t control for Z (the mediator)?
Control for Z?
Graph the Data
Fit the Models
Interpreting the Pipe Simulation
What we observed:
Without controlling for Z: We see the total causal effect of X on Y (through Z)
After controlling for Z: The effect of X disappears because Z is the mechanism
Lesson: When you have a pipe (mediator), controlling for it blocks the causal pathway you’re interested in. Don’t control for mediators if you want the total effect!
# The correct model for the total effect of READ:lm(COMPREHEND ~ READ, data = df)
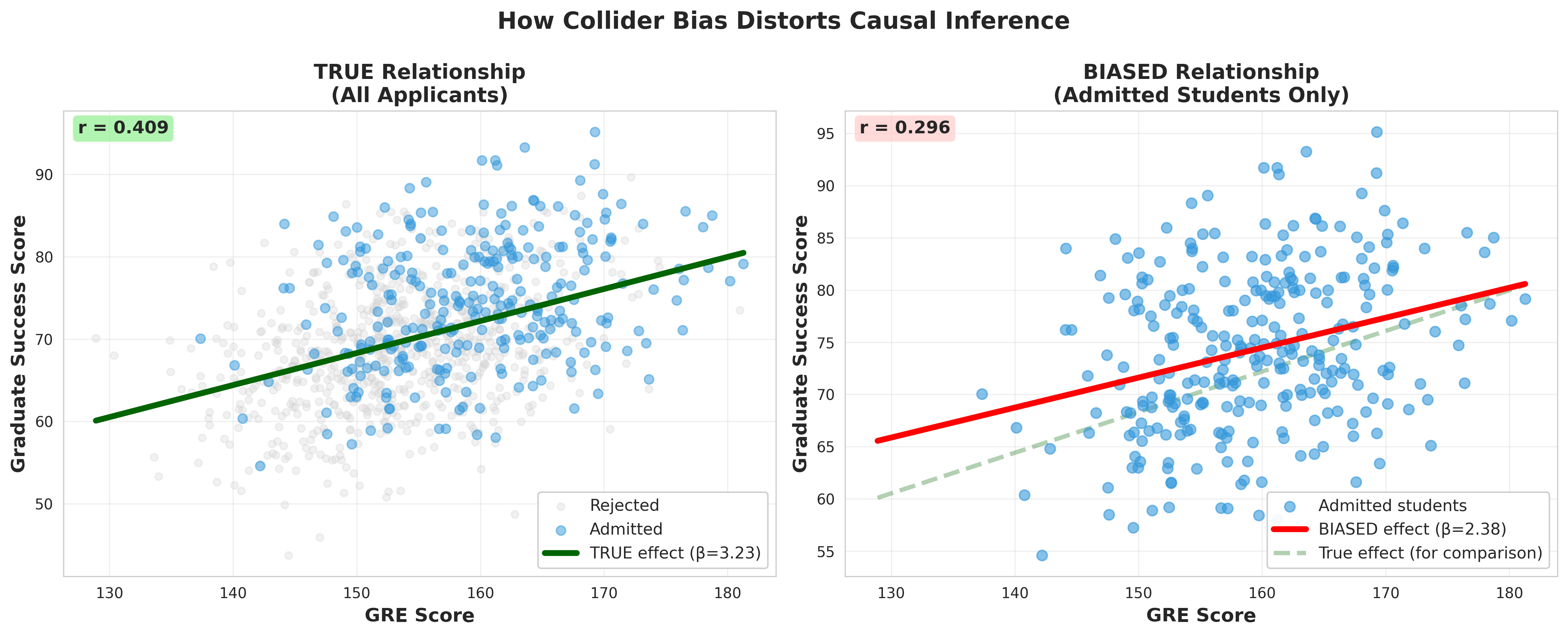
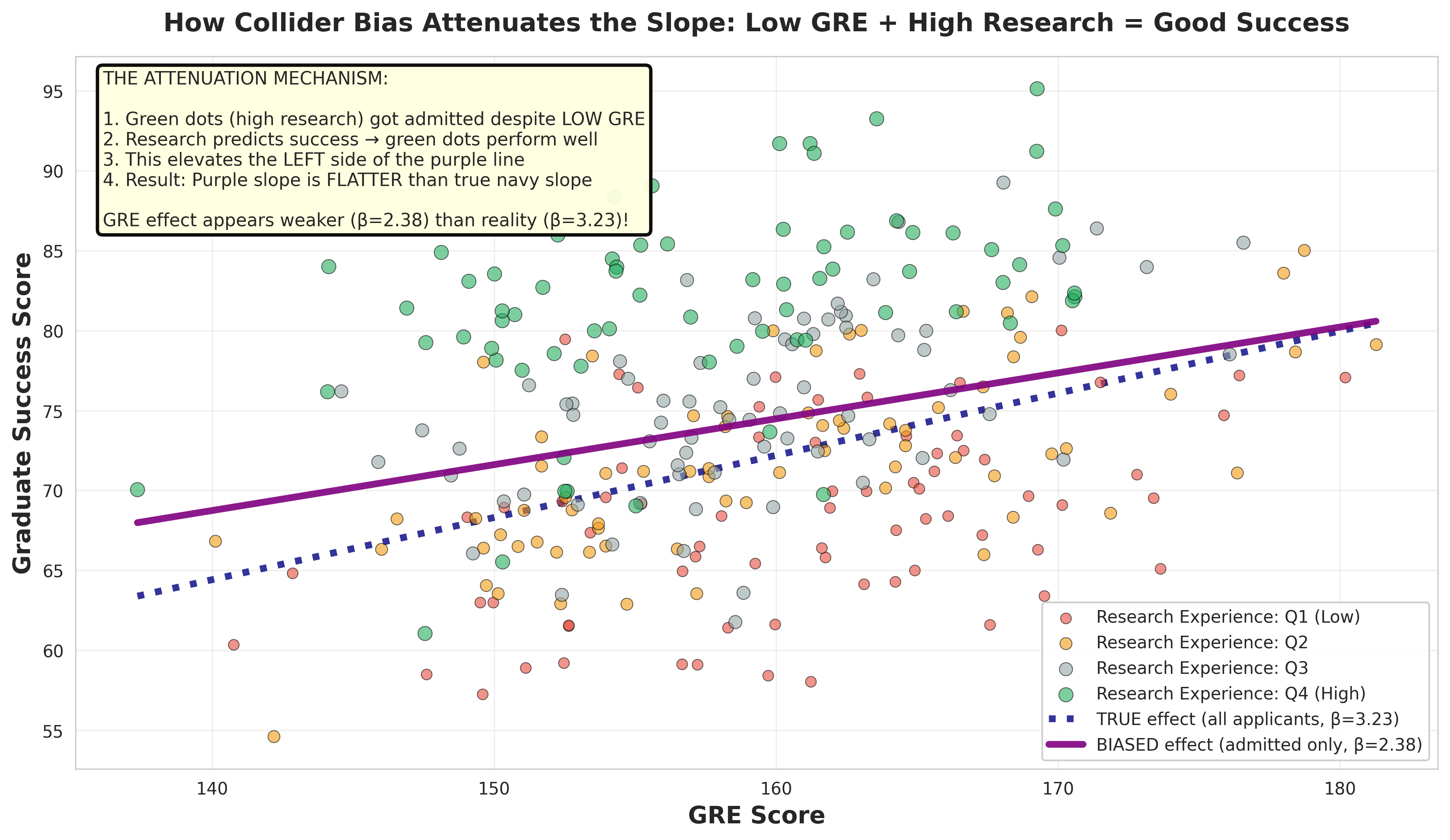
The Collider
Colliders are a Scary Scenario
Key Property: A collider is caused by two or more variables. By default, collider paths are blocked.
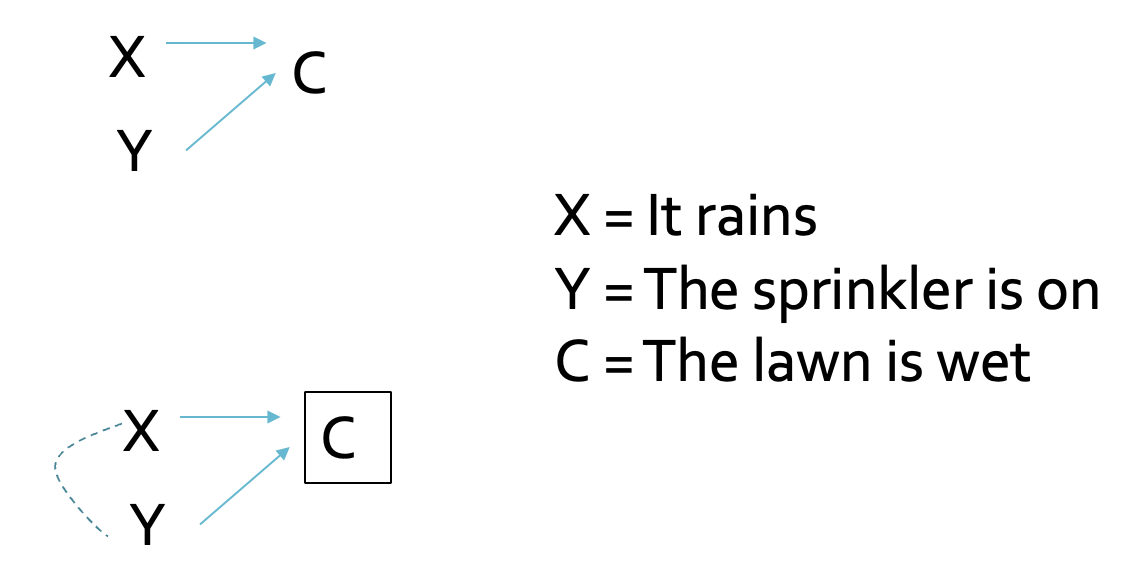
An Intuitive Example of a Collider
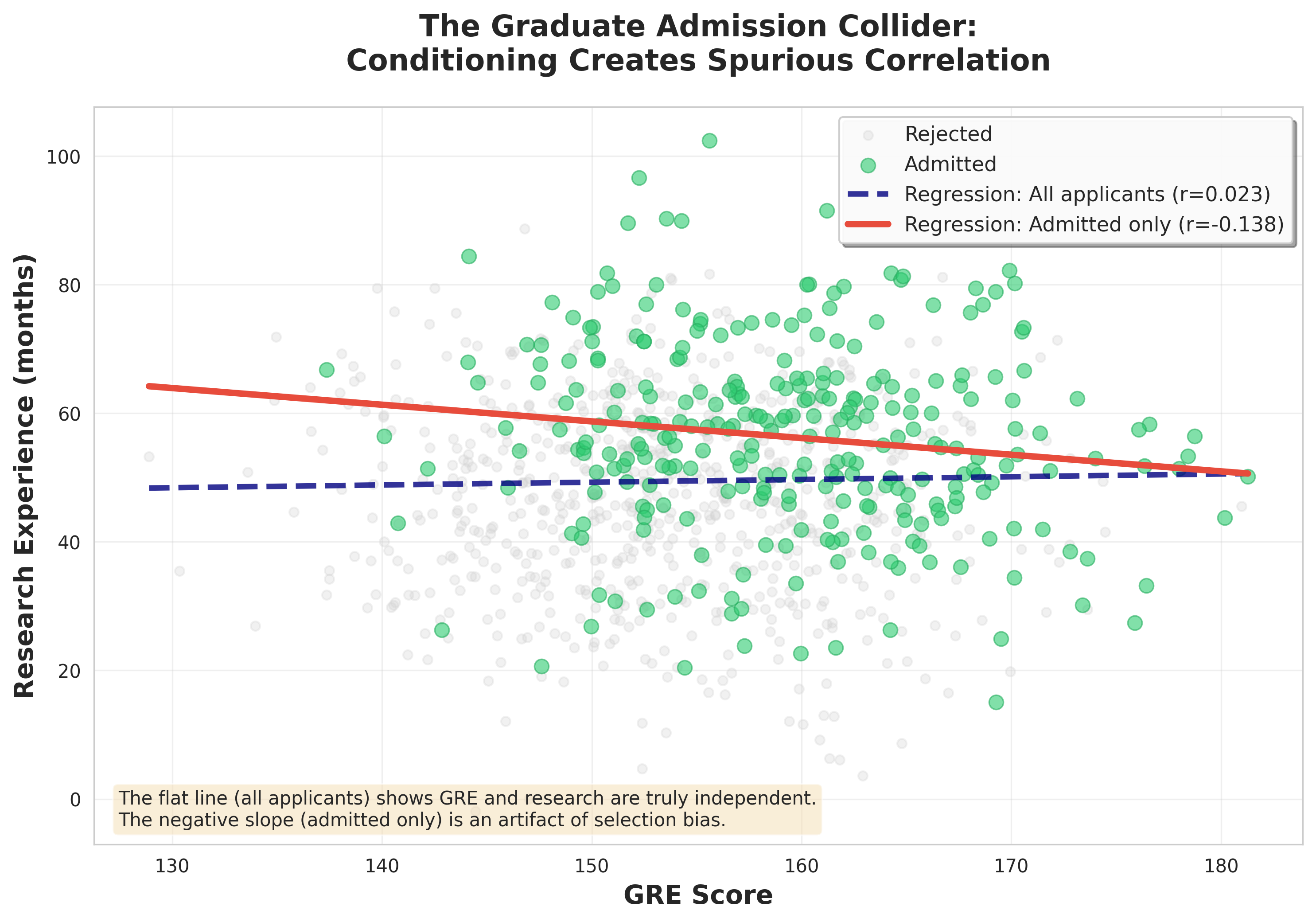
Question: Are “Rain” and “Sprinkler On” correlated?
Intuition: Conditioning on a Collider
Scenario 1 - Not conditioning on “Lawn Wet”:
Rain and Sprinkler are independent
No correlation expected
Scenario 2 - Conditioning on “Lawn Wet = Yes”:
If we know the lawn is wet AND it didn’t rain…
Then the sprinkler must have been on!
This creates a spurious negative correlation
Lawn Simulation: Make a Prediction
Before running the simulation, predict:
What will be the correlation between Rain and Sprinkler in the full data?
What will be the correlation when we condition on Lawn Wet?
Lawn Simulation Results
Proper Handling of Colliders
By default, collider paths are blocked, meaning they do not create a spurious association between the exposure and the outcome.
But beware: If you condition on a collider, you will open a back door path and create a spurious association.
Critical Rule
Never condition a collider unless you have a very good reason and understand the implications!
# The correct model:lm(COMPREHEND ~ READ, data = df)# DO NOT include ACTUAL_READ in the model!
Why?
By conditioning on ACTUAL_READ, you open a non-causal path between READ and MOTIVATION that would otherwise remain blocked (collider bias)
This creates a spurious association between READ and COMPREHEND, undermining the causal interpretation
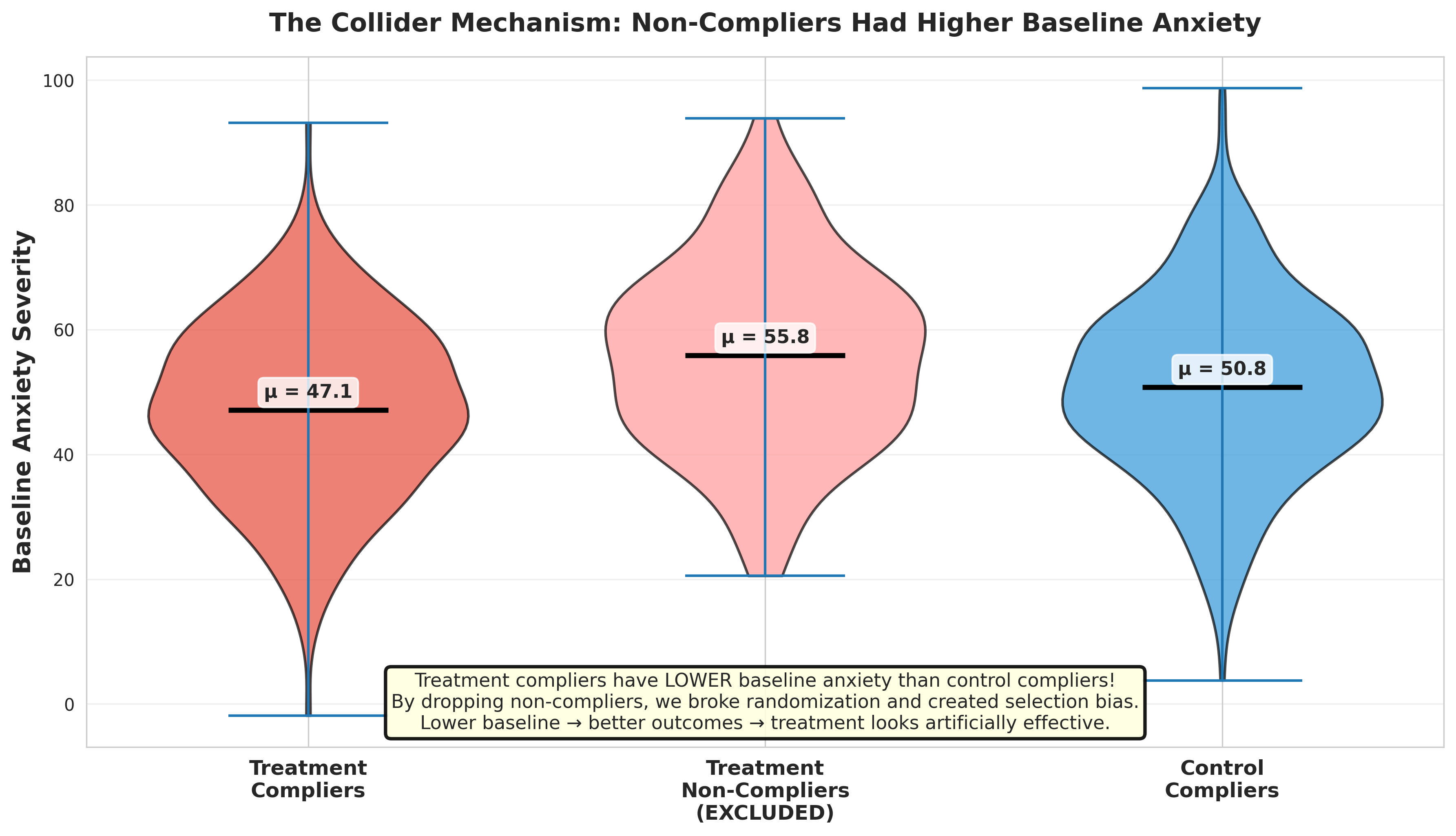
Revel in the beauty of your experiment, and don’t include any post-treatment variables! Don’t drop non-compliers and don’t control for non-compliance in a model.
Take Home Message for Experiments
Many researchers make this mistake! Understanding DAG structures helps you avoid it.
Another Common Collider: Dropout
In field experiments, participants often drop out before outcome measurement.