| Variable | Class | Description |
|---|---|---|
| id | double | Athlete ID |
| name | character | Athlete name |
| sex | character | Athlete sex |
| age | double | Athlete age |
| height | double | Athlete height in cm |
| weight | double | Athlete weight in kg |
| team | character | Country/Team competing for |
| noc | character | NOC region |
| games | character | Olympic Games name |
| year | double | Year of Olympics |
| season | character | Season (either winter or summer) |
| city | character | City of Olympic host |
| sport | character | Sport |
| event | character | Specific event |
| medal | character | Medal (Gold, Silver, Bronze, or NA) |
PSY 652: Research Methods in Psychology I
Probability Distributions
The data
We’ll consider data that covers the modern Olympic Games, from Athens 1896 to Rio 2016, and was originally scraped from www.sports-reference.com. It was then formatted for data analysis by Kaggle, a popular platform for data science competitions.

What is a Probability Mass Function (PMF)?
A probability mass function (PMF) provides the probability that a discrete random variable takes on a specific value. Recall the blood type example from the Module 6 handout.

What is the probability that a randomly selected individual from the population will have type AB blood?
An example from the Olympics data
A very small percentage of the global population gets the opportunity to participate in the Olympic Games, with an even more limited number going on to compete in multiple Games (e.g., more than one year). We can create an empirical PMF for number of appearances at Olympic Games.
For example, Dara Torres appeared in 5 Games (1984, 1988, 1992, 2000, 2008).

Carl Lewis appeared in 4 Games (1980, 1984, 1988, 1992).

Summary for discrete variables


What is a Probability Density Function?
A probability density function (PDF) is used to describe the distribution of a continuous random variable.
Unlike a discrete variable, where we can directly calculate the probability of specific outcomes using a PMF (e.g., the probability of two appearances at Olympic Games), a PDF represents the probability that a continuous variable falls within a particular interval.

Why do we need a different function?
For a continuous variable, the probability of the variable taking any exact value is technically zero, because there are infinitely many possible values it could take.
Instead, the PDF helps us calculate the probability that the variable falls within an interval.
The area under the curve of the PDF over a given range represents the probability of the variable being in that interval.

Interpreting the CDF

The value of the CDF function at any point represents the cumulative probability up to that point. The ECDF ranges from 0 to 1, and the y-axis gives the probability that a randomly selected observation is less than or equal to the corresponding x-value.
Comparison of PDF and CDF
The graphs below both display the \(P(BMI \leq 20)\)


For the PDF, the total area under the curve represents 100% of the distribution of BMI values for male Olympic athletes. The pink shaded area corresponds to the probability that a randomly selected male athlete has a BMI of 20 or less, which is approximately 7% of the total distribution.
Comparison of PDF and CDF
The graphs below both display the \(P(BMI \geq 30)\)


Comparison of PDF and CDF
The graphs below both display the \(P(20 \leq BMI \leq 30) = P(BMI \leq 30) - P(BMI \leq 20)\)


Practice with ECDF
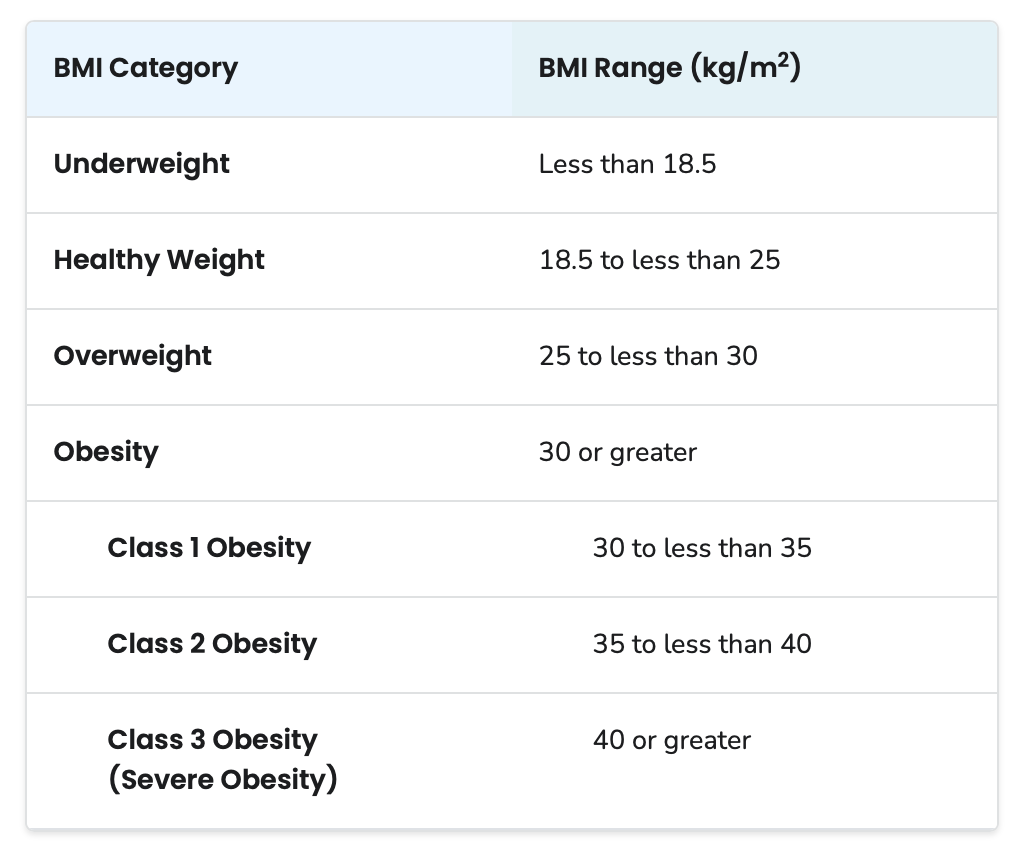
The chart below presents the recommendations for a healthy BMI. Using this chart, please answer the following two questions (next two slides).
Is BMI of male Olympic athletes normally distributed?

Is BMI of male Olympic swimmers normally distributed?

Using the Normal Distribution, what is the probability that a male Olympic swimmer will have a BMI less than or equal to 19?

What is the probability that a male Olympic swimmer will have a BMI greater than or equal to 22?

What is the probability that a male Olympic swimmer will have a BMI less than or equal to 18.5 OR greater than or equal to 25?

What is the probability that a male Olympic swimmer will have a BMI between 21 and 23?

A graph to depict the 90th percentile

Graph of a Standard Normal Distribution

95% of a normal distribution falls within 1.96 standard deviations of the mean. A z-score of −1.96 means the value is 1.96 standard deviations below the mean. A z-score +1.96 means the value is 1.96 standard deviations above the mean.
What is the probability that a z-score is \(\leq -1.96\)?
Here, we want to solve for a probability, so we use pnorm():
About 2.5% of scores are less than or equal to -1.96.

What is the probability that a z-score is \(\geq +1.96\)?
About 2.5% of scores are greater than or equal to +1.96.

Summary for the Standard Normal Distribution

This is a key concept in statistics that we’ll rely on a lot in the coming Modules, as it highlights the range within which most values fall in a standard normal distribution — approximately 95% of data points.