PSY 652: Research Methods in Psychology I
Introduction to Probability
Fake news

With the rise of online news and social media platforms that allow users to share articles with minimal oversight — fake, misleading, and biased news has become widespread.
To illustrate this, we will look at a sample of 150 articles that were shared on Facebook during the run-up to the 2016 U.S. presidential election. The data were collected as part of a study called “FakeNewsNet: A Data Repository with News Content, Social Context and Spatialtemporal Information for Studying Fake News on Social Media” (there’s a link to the study under resources on the Week 4 page). These data are used in the wonderful book titled Bayes Rules (also linked on the Week 4 page), and the data set is part of the bayesrules package.
A diagram to depict the Sample Space for \(FAKE\)
Let’s define event \(FAKE\) as drawing an article that is fake. This is represented by the blue circle in the diagram. The complement of \(FAKE\), also referred to as \(FAKE^c\), represents the event of drawing an article that is real. In the diagram, this is represented by the area outside the blue circle but within the rectangle, which signifies the entire sample space. In other words: \(FAKE^c\) = \(REAL\).

Probability Mass Function (PMF)
A PMF gives the probability of each possible outcome of a discrete random variable.

The Law of Total Probability states that the sum of the probabilities of all elementary events in a sample space is 1. Here, we see an illustration of this, 0.4 + 0.6 = 1.0.
The experiment

Imagine that we took 60 blue marbles and labeled each one with a number that corresponds to a fake article. Then, we took 90 red marbles and labeled each one with a number that corresponds to a real article.
We put all 150 marbles into a machine that can mix them up completely, like a lottery machine. This machine represents randomness and ensures that every marble has an equal chance of being selected.
After thoroughly mixing the marbles, we pull the lever and draw one marble at random. The color of the marble tells us the type of article:
- If we draw a blue marble, it represents selecting a fake article.
- If we draw a red marble, it represents selecting a real article.
A diagram to depict the Sample Space for \(WITH!\)

The probability of drawing an article with an !, \(P(WITH!)\), is 18/150 = 0.12.
The probability of drawing an article without an !, \(P(WITH!^c)\), is 132/150 = 0.88.
A Cross-Tabulation/Contingency Table
The values displayed in this table represent the cell totals when considering the cross tabulation (i.e., contingency table) between type and exclamation. Find the first presented table on your worksheet (it will look just like this), and fill in the row and column margins, as well as the grand total to complete all counts.

Completed table
![]()
The Venn diagram visually represents the overlap between the two categories: “FAKE” and “WITH !”. The blue circle represents fake articles, and the green circle represents articles with an exclamation mark. How might we translate the information in the table to the Venn diagram?
Overlapping circles
| Cross table with fake articles highlighed | |||
|---|---|---|---|
type
|
Total | ||
| real | fake | ||
| exclamation | |||
| without ! | 88 | 44 | 132 |
| with ! | 2 | 16 | 18 |
| Total | 90 | 60 | 150 |
| Cross table with ! articles highlighed | |||
|---|---|---|---|
type
|
Total | ||
| real | fake | ||
| exclamation | |||
| without ! | 88 | 44 | 132 |
| with ! | 2 | 16 | 18 |
| Total | 90 | 60 | 150 |

Raw numbers and proportions/probabilities
We can translate these raw counts into proportions. For each of the four main cells, compute the proportion of total articles represented by the cell. Please complete this table on your worksheet.

Complete the margins and grand total

Cross-tab of counts (left) and proportions (right)

Labeled table

Conditional probability of an ! given the article is fake
Event A: The article title has an exclamation point
Event B: The article is fake
\(P(\text{A} \mid \text{B}) = P(\text{WITH!} \mid \text{FAKE}) = \frac{P(\text{WITH!} \cap \text{FAKE})}{P(\text{FAKE})}\)

\(P(WITH!|FAKE)\)
Q1: Given an article is fake, what is the probability that the title will have an exclamation point?
- With counts: 16/60 = 0.2667; With probabilities: 0.1067/0.40 = 0.2667
\(P(WITH!|FAKE^c)\)
Q2: Given an article is real, what is the probability that the title will have an exclamation point?
- With counts: 2/90 = 0.0222; With probabilities: 0.0133/0.60 = 0.0222
\(P(FAKE|WITH!)\)
Q3: Given an article has an exclamation point, what is the probability that it’s fake?

- With counts: 16/18 = 0.8890; With probabilities: 0.1067/0.12 = 0.8890
An ! point in the title as a test for a fake article
Let’s imagine that you created an algorithm to test for fake articles on Facebook. Your “test” is whether or not there is an ! in the title. Let’s see how well this test detects a fake article.
Positive test = ! in title
Disease + = article is fake
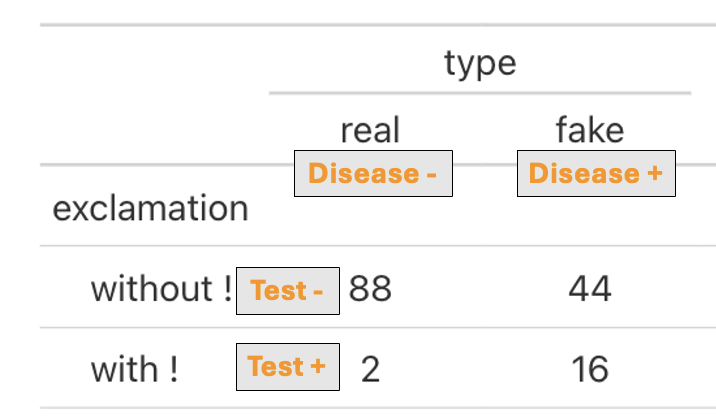
Possibilities
True Positive (TP): The number of fake articles correctly identified as fake (with an exclamation mark).
True Negative (TN): The number of real articles correctly identified as real (without an exclamation mark).
False Positive (FP): The number of real articles incorrectly identified as fake (with an exclamation mark).
False Negative (FN): The number of fake articles incorrectly identified as real (without an exclamation mark).
Possibilities with answers
True Positive (TP): The number of fake articles correctly identified as fake (with an exclamation mark).
True Negative (TN): The number of real articles correctly identified as real (without an exclamation mark).
False Positive (FP): The number of real articles incorrectly identified as fake (with an exclamation mark).
False Negative (FN): The number of fake articles incorrectly identified as real (without an exclamation mark).

Tips for keeping things straight
T or F (True or False): This indicates whether the test result correctly matches the actual outcome (ground truth). “True” means the test result correctly identifies the status (either positive or negative), while “False” means the test result is incorrect.
N or P (Negative or Positive): This refers to the test result itself. “Positive” indicates the test result is positive (e.g., speculating the presence of a condition), and “Negative” indicates the test result is negative (e.g., speculating the absence of a condition).
Sensitivity, Specificity, and Positive Predictive Value
Sensitivity: The probability of the test (presence of an !) correctly identifying a fake article, given the article is fake. This is also called the true positive rate.
\[ \frac{\text{TP}}{\text{TP} + \text{FN}} \]
Specificity: The probability of the test (presence of an !) correctly identifying a real article, given the article is real. This is also called the true negative rate.
\[ \frac{\text{TN}}{\text{TN} + \text{FP}} \]
Positive Predictive Value (PPV): The probability that an article is fake given that it has an exclamation point.
\[ \frac{\text{TP}}{\text{TP} + \text{FP}} \]
Sensitivity, Specificity, and Positive Predictive Value
Sensitivity: The probability of the test (presence of an !) correctly identifying a fake article, given the article is fake. The test is not very sensitive; it misses a large number of fake articles, as 44 of them are incorrectly categorized as real (False Negatives, FN).
\[ \frac{\text{TP}}{\text{TP} + \text{FN}} = \frac{16}{16 + 44} \approx 0.267 \]
Specificity: The probability of the test (presence of an !) correctly identifying a real article, given the article is real. The test is highly specific, meaning that when the article is real, the test rarely misidentifies it as fake (only 2 False Positives, FP).
\[ \frac{\text{TN}}{\text{TN} + \text{FP}} = \frac{88}{88 + 2} \approx 0.978 \]
PPV: The probability that an article is fake given that it has an exclamation point. Although the test (exclamation mark as a predictor) has low sensitivity and misses many fake articles, when it does flag an article as potentially fake, it is highly likely to be correct. In this context, the test does a very good job of correctly identifying fake articles when it produces a positive result (the presence of an exclamation mark). However, because it misses many fake articles (low sensitivity), it is not a comprehensive screening tool on its own.
\[ \frac{\text{TP}}{\text{TP} + \text{FP}} = \frac{16}{16 + 2} \approx 0.889 \]