orig_ATP_W112 <- read_spss(here("data", "ATP_W112.sav"))Apply and Practice Activity
Importing and Exploring Pew Research Center Data
Introduction
For your final project, you will identify and explore a dataset of your choosing. This could be a dataset provided by your advisor, one you have already collected, or a publicly available dataset that aligns with your interests.
In this activity, we’ll walk through the process of accessing publicly available data using an example from the Pew Research Center. You may find a number of compelling datasets there that could work well for your final project.
Earlier in the course, we replicated this graph produced by the Pew Research Center by simply recording the data printed on the figure to produce our own data frame:
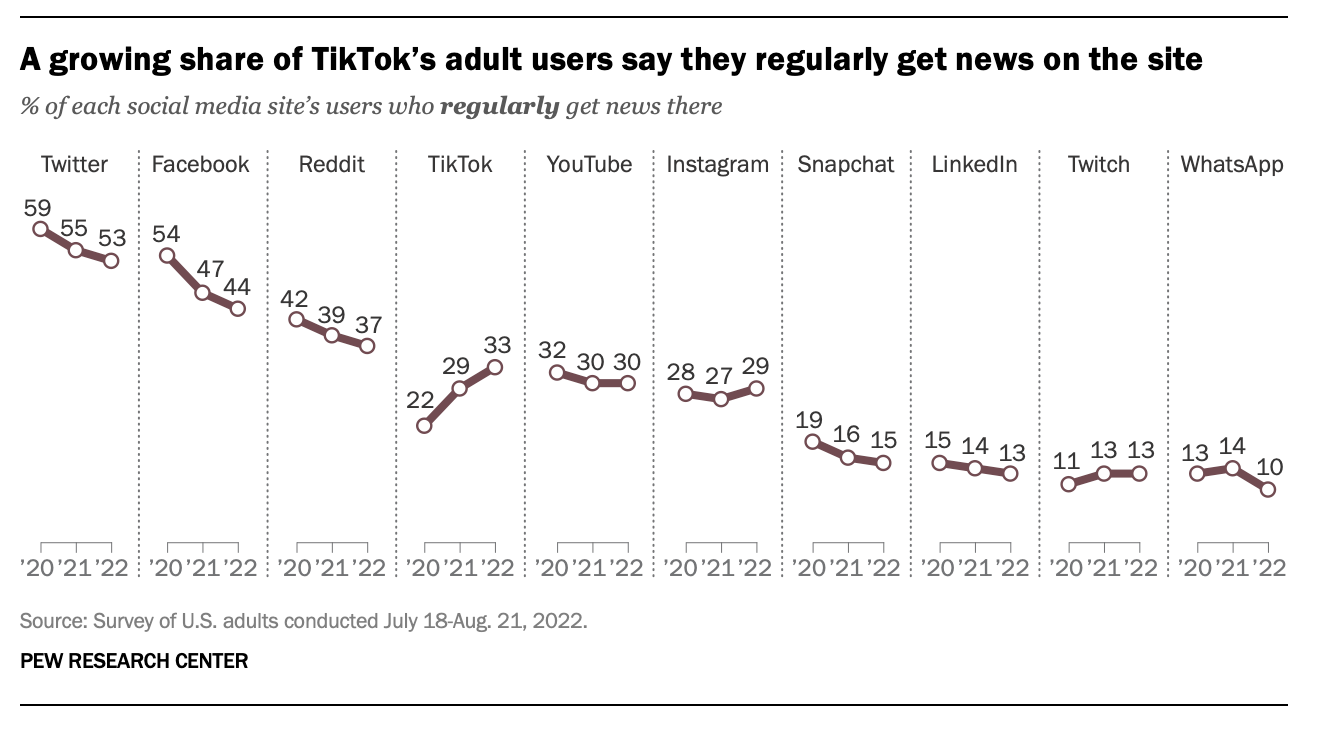
Now, you’ll see how to download the actual data frame to obtain the raw data. For simplicity, we’ll focus on the survey that produced the 2022 data for the graph.
Step by Step Directions
Step 1
Set up a Pew Research Center account.
In order to download data from the Pew Research Center, you need to create an account. Please read this brief article on Pew data availability and how to create an account. Then create an account so you can download data.
Step 2
Obtain the data.
We need to find and import the necessary data frame. You can peruse the data frames that are available at this link. For this tutorial, we need to download the data frame located here. It is from Wave 112 of the American Trends Panel. Go to the link just mentioned, make sure you’re logged into your Pew Research Center account, then click Download Dataset. It will produce a zipped folder. Drag the zipped folder from your downloads folder to your desktop, then unzip the file (depending on your operating system, the folder may be unzipped automatically).
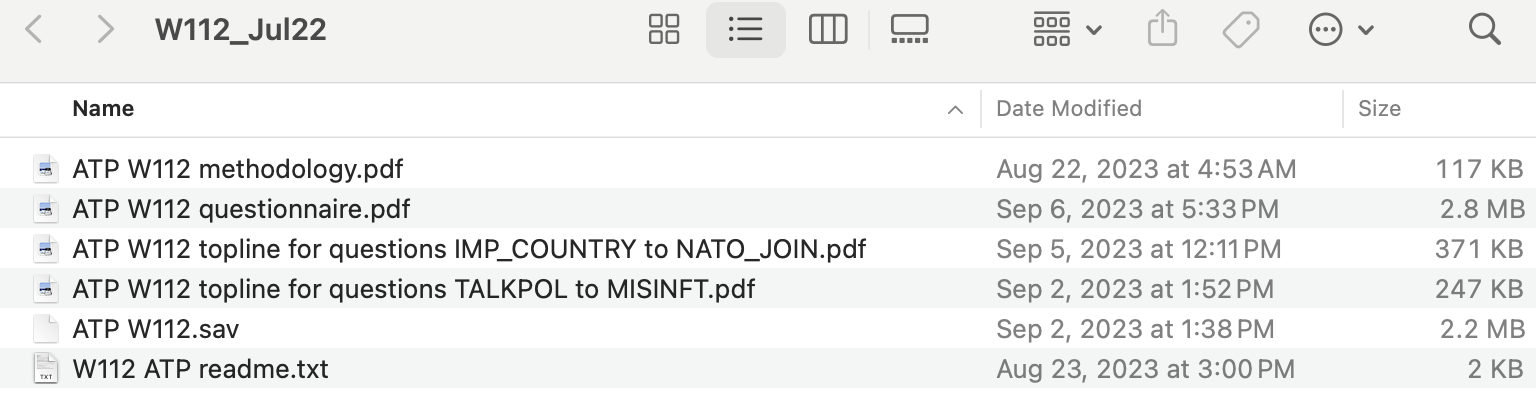
Once you download and unzip the file, you can click on it, and the contents will look like this:
Step 3
Prepare the data files.
The first four files and the last file are documentation, these files contain important information about the data. When you conduct your personal Pew Research Center project, it will be important to read through all of the documentation files associated with the survey that you select. The fifth file, called ATP W112.sav, is the data frame. Mostly, Pew Research Center saves their data frames as SPSS files (.sav is a SPSS data frame). We can easily convert this file to a R data frame, but before we get to that, it’s useful to change the name of the file to remove the space in the data file name. Inside your folder (that you downloaded, unzipped, and move to your desktop), rename the SPSS data file to ATP_W112.sav (i.e., add a single underscore between ATP and W112).
Step 4
Create a Posit Cloud Project.
Let’ set up a new Posit Cloud project. Log into your Posit Cloud account. First, exit out of the foundations project if necessary, and return to Your Workspace. Then, click on the New Project button, then choose New RStudio Project. At the top of the RStudio screen — where it says “Untitled Project” — click to provide the project a name. Call it pew_research_center.
In the lower right quadrant of your RStudio session — under the Files tab — create three primary folders in your project.
Right under the Files tab, there is a Folder icon with a green plus — click on this to create a new folder. Enter the folder name data. Click OK.
Create a second folder using the same method — call this one documentation.
Last, create a third folder using the same method — call this one programs.
Step 5
Upload the Pew files to the Posit Cloud pew_research_center project.
Still working in the lower right quadrant of your RStudio session — under the Files tab, now we will upload the files that you downloaded from the Pew Research Center to the folders you just created (and specified below) by using the Upload button in RStudio (it’s just a couple icons to the right of the Folders icon).
- Click on the data folder that you just created. Then, click the Upload button. A box will pop up. Under File to Upload, click Choose File and navigate to the file called ATP_W112.sav that lives in the folder downloaded from the Pew Research Center site that you put on your desktop. Then click OK. Now, the data frame that we will soon import to R exists in the data folder of your project.
- Click on the documentation folder that you just created. Then, click the Upload button. A box will pop up. Under File to Upload, click Choose File and navigate to the file called called ATP W112 methodology.pdf that lives in the folder downloaded from the Pew Research Center site that you put on your desktop. Then click OK. Do the same for the other four documentation files. Now, the documentation files that are needed for your project are all handy in the documentation folder of your project.
Step 6
Create a new Quarto analysis notebook.
Now we’re ready to start a new Quarto document to perform our analysis (i.e., a Quarto analysis notebook). Click File -> New File -> Quarto Document. A dialog box will pop up — in it, give your new document a Title — Pew Research Center Tutorial, then type your name (beside Author). Uncheck the box beside “Use visual markdown editor.” Then click Create Empty Document.
Once the file is created, click File -> Save As, then save your Quarto analysis notebook in the programs folder of the pew_research_center project. Name it pew_tutorial.qmd.
Step 7
Set up your YAML header
In your .qmd file just created, set up your YAML header as you like. You can leave it very simple (just as it is now with the basic set up) or you can explore a bit. Here’s a “go to” set up that I use — but you can modify it as you like. Just remember that all of the instructions must stay between the three dashed lines. The indentations for format: need to be precise — with two spaces to begin html and two additional spaces to begin theme and embed-resources. You’ll get a warning/error notification if something isn’t right. Recall that Quarto has different themes for your report — here, I’ve selected minty — but you can choose one you like by perusing the options here.
title: "Pew Research Center Tutorial"
author: "Kimberly L. Henry"
format:
html:
theme: minty
embed-resources: true
df-print: paged
toc: true
editor: sourceBreakdown of each instruction in the YAML header
title: "Pew Research Center Tutorial"Purpose: Sets the title of the document.
Example Output: “Pew Research Center Tutorial” will appear as the main title at the top of the rendered document.
author: "Kimberly L. Henry"Purpose: Specifies the author of the document.
Example Output: “Kimberly L. Henry” will be listed as the author.
format:Purpose: Defines the output format and its options.
Sub-options:
html:: Indicates that the document will be rendered as an HTML file.theme: minty: Applies the “minty” theme to the HTML document, which affects its visual style and design.embed-resources: true: Ensures that all resources (like images) are embedded directly in the HTML file. This makes the HTML file self-contained and easier to share.
df-print: pagedPurpose: Configures how data frames (tables) are displayed in the document.
Example Output: Large data frames will be displayed in a paginated format, allowing users to navigate through them page by page.
toc: truePurpose: Adds a Table of Contents (TOC) to the document.
Example Output: A TOC will be automatically generated, listing the sections and subsections of the document with links to each part.
editor: sourcePurpose: Sets the default editor mode in RStudio.
Example Output: Opens the document in “source” mode, which displays the raw Markdown and code rather than a preview.
If you want to add styling to your Quarto document via the YAML header — check out my basic tips on setting up a YAML with embedded resources and other styling. Or, check out these advanced options.
Step 8
Load the packages that we will need.
Underneath the YAML header, create a first level header:
# Load libraries
Then, create a R code chunk (click on the Green C with a plus sign). Inside the code chunk load the following packages using the library() function: here, skimr, haven, labelled, survey, gt and tidyverse.
Be sure to run the code chunk so the packages are available in your session.
Step 9
Import the data frame.
Now we’re ready to import the data frame. Underneath the section where you loaded the packages, create a first level header:
# Import data
Then, create a R code chunk. Inside the code chunk, import the data frame called ATP_W112.sav. Your code chunk should look like this:
When you created your project, R created a .Rproj folder at the root of the project directory. Working from this root, the data frame that you imported lives in the data folder. Therefore, the here() function tells R to look for the data frame called ATP_W112.sav, a SPSS file, in your data folder. The read_spss() function from the haven package tells R to import the SPSS file. Once you run the code chunk, an R version of the data frame will be created, and you will see it in the Environment tab of the upper right quadrant of RStudio.
Step 10
Examine the data frame.
Ultimately, we need to create a subsetted and formatted version of the data frame that has just the variables that we need for our analysis. We need to take a look at the questionnaire to figure out what variables are needed. For this tutorial, we’re keeping it simple and just considering the social media use of the respondents.
Open up the file called ATP W112 questionnaire.pdf which you put into your documentation folder. Scroll down, or use the find tool, to get to the description of the variable SMUSE. The description of this variable will look like this:

We can take a look at a description of the variables as well as the head of a subsetted data frame with variables that are in this section with the following code. Study the code and outputs. Following the outputs is a description of what the code accomplishes.
# description of variables in section
orig_ATP_W112 |>
select(starts_with("SMUSE")) |>
look_for() |>
convert_list_columns_to_character() |>
gt()| pos | variable | label | col_type | missing | levels | value_labels |
|---|---|---|---|---|---|---|
| 1 | SMUSE_a_W112 | SMUSE_a_W112. Please indicate whether or not you ever use the following websites or apps. Facebook | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 2 | SMUSE_b_W112 | SMUSE_b_W112. Please indicate whether or not you ever use the following websites or apps. YouTube | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 3 | SMUSE_c_W112 | SMUSE_c_W112. Please indicate whether or not you ever use the following websites or apps. Twitter | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 4 | SMUSE_d_W112 | SMUSE_d_W112. Please indicate whether or not you ever use the following websites or apps. Instagram | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 5 | SMUSE_e_W112 | SMUSE_e_W112. Please indicate whether or not you ever use the following websites or apps. Snapchat | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 6 | SMUSE_f_W112 | SMUSE_f_W112. Please indicate whether or not you ever use the following websites or apps. WhatsApp | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 7 | SMUSE_g_W112 | SMUSE_g_W112. Please indicate whether or not you ever use the following websites or apps. LinkedIn | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 8 | SMUSE_h_W112 | SMUSE_h_W112. Please indicate whether or not you ever use the following websites or apps. Pinterest | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 9 | SMUSE_i_W112 | SMUSE_i_W112. Please indicate whether or not you ever use the following websites or apps. TikTok | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 10 | SMUSE_j_W112 | SMUSE_j_W112. Please indicate whether or not you ever use the following websites or apps. Reddit | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 11 | SMUSE_k_W112 | SMUSE_k_W112. Please indicate whether or not you ever use the following websites or apps. Twitch | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused | |
| 12 | SMUSE_l_W112 | SMUSE_l_W112. Please indicate whether or not you ever use the following websites or apps. Nextdoor | dbl+lbl | 196 | [1] Yes, use this; [2] No, don’t use this; [99] Refused |
# head of data frame with variables in the section
orig_ATP_W112 |>
select(starts_with("SMUSE")) |>
head(n = 25)What is this code accomplishing?
The look_for() function from the labelled package is useful for creating a listing of the variables, labels, and values. The gt() function from the gt package puts the information into a nice looking table. Here we see that each of the social media use variables have a similar format — where they start with the prefix SMUSE then denote a letter which corresponds to the social media site inquired about (e.g., _a refers to Facebook). All of the variables end in the suffix _W112 to denote the survey wave. So, for example, the variable SMUSE_a_W112 corresponds to whether or not the respondent reported using Facebook. From the look_for() output, we see that a 1 means “Yes, use this” and 2 means “No, don’t use this”, and 99 means “Refused.” It’s critical to note where variables have coded values that will need to be recoded prior to analysis (e.g., it’s likely that we’d want to recode scores of 99 to system missing).
Notice in the look_for() output that there are 196 people who are listed as missing for all of these variables. By looking at the documentation — we see that only people who indicated that they have internet were asked these questions. For people with internet — the variable XTABLET_W112 equals 2 (this variable is equal to 1 if the respondent didn’t have internet and had to be sent a Pew tablet to complete the survey). This information can be viewed with the following code:
orig_ATP_W112 |>
select(XTABLET_W112) |>
look_for() |>
convert_list_columns_to_character() |>
gt()| pos | variable | label | col_type | missing | levels | value_labels |
|---|---|---|---|---|---|---|
| 1 | XTABLET_W112 | XTABLET_W112. Flag to identify non-internet households that were provided a tablet | dbl+lbl | 0 | [1] Tablet HH; [2] Non-tablet HH |
A conscientious analyst always verifies missing cases. For example, we can use the code below to check that our understanding of this feature of the survey is correct:
orig_ATP_W112 |>
select(XTABLET_W112, starts_with("SMUSE")) |>
group_by(XTABLET_W112) |>
count(SMUSE_a_W112) In the output above, we see that when XTABLET_W112 equals 1 (which means the respondent didn’t have internet and was given a Pew tablet to complete the survey — represented by the top row in the table) then SMUSE_a_W112 is NA (system missing) — and there are 196 of these people. When XTABLET_W112 equals 2 (the bottom three rows in the table) then SMUSE_a_W112 equals 1, 2 or 99. This matches our expectation.
Additionally, for each social media site that the participant indicated that they use, they were asked if they regularly get their news from this site. You can find this question set in the ATP W112 questionnaire.pdf documentation, here’s a screen shot:

Here’s a summary of these variables, with a description first and the head of the subsetted data frame for variables in this section second. Please study the output.
# description of variables in section
orig_ATP_W112 |>
select(starts_with("SOCIALNEWS2")) |>
look_for() |>
convert_list_columns_to_character() |>
gt()| pos | variable | label | col_type | missing | levels | value_labels |
|---|---|---|---|---|---|---|
| 1 | SOCIALNEWS2_a_W112 | SOCIALNEWS2_a_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. Facebook | dbl+lbl | 3528 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 2 | SOCIALNEWS2_b_W112 | SOCIALNEWS2_b_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. YouTube | dbl+lbl | 1921 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 3 | SOCIALNEWS2_c_W112 | SOCIALNEWS2_c_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. Twitter | dbl+lbl | 8869 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 4 | SOCIALNEWS2_d_W112 | SOCIALNEWS2_d_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. Instagram | dbl+lbl | 6646 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 5 | SOCIALNEWS2_e_W112 | SOCIALNEWS2_e_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. Snapchat | dbl+lbl | 9659 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 6 | SOCIALNEWS2_f_W112 | SOCIALNEWS2_f_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. WhatsApp | dbl+lbl | 8856 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 7 | SOCIALNEWS2_g_W112 | SOCIALNEWS2_g_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. LinkedIn | dbl+lbl | 7702 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 8 | SOCIALNEWS2_i_W112 | SOCIALNEWS2_i_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. TikTok | dbl+lbl | 9054 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 9 | SOCIALNEWS2_j_W112 | SOCIALNEWS2_j_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. Reddit | dbl+lbl | 9831 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 10 | SOCIALNEWS2_k_W112 | SOCIALNEWS2_k_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. Twitch | dbl+lbl | 11458 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused | |
| 11 | SOCIALNEWS2_l_W112 | SOCIALNEWS2_l_W112. Do you REGULARLY get news or news headlines on any of the following social media sites or apps? By news we mean information about events and issues that involve more than just your friends or family. Nextdoor | dbl+lbl | 9269 | [1] Yes, regularly get news on this; [2] No, don’t regularly get news on this; [99] Refused |
# head of data frame with variables in the section
orig_ATP_W112 |>
select(starts_with("SOCIALNEWS2")) |>
head(n = 25)So, upon inspecting the output, for each variable the respondent should be observed if the social media site was used to receive news, and not observed if the social media site was NOT used to receive news OR if the respondent didn’t have internet OR if the respondent refused to answer the question about Facebook use. Let’s verify that our understanding of this is accurate for Facebook:
orig_ATP_W112 |>
select(XTABLET_W112, starts_with("SMUSE"), starts_with("SOCIALNEWS2")) |>
group_by(XTABLET_W112, SMUSE_a_W112) |>
count(SOCIALNEWS2_a_W112) The table produces what we’d expect. The variable SOCIALNEWS_a_W112 is missing (NA) if the respondent didn’t have internet (XTABLET_W112 equals 1), it is also missing if the respondent indicated that they don’t use Facebook or if they refused to answer the question about Facebook use (SMUSE_a_W112 equals 2 or 99), it is observed if they said they used Facebook (SMUSE_a_W112 equals 1). Notice that 46 respondents said they used Facebook, but they refused to answer the question about whether they get news from Facebook (and are thus recorded as a 99 in the data frame for variable SOCIALNEWS_a_W112).
Step 11
Subset and format data frame.
Now that we’ve taken the time to ensure we understand the variables and that the variable responses are recorded as we would expect, let’s create a new data frame that has just the variables related to social media use that we need to consider here. We’ll also keep the variables called QKEY (the respondent ID) and WEIGHT_W112 (a survey weight which we’ll learn more about these later).
In your Quarto analysis notebook, create a first level header:
# Prepare the data frame for analysis
Then a second level header:
## Subset the data
Then, create a R code chunk. Inside the code chunk, paste the following code:
my_W112_df <-
orig_ATP_W112 |>
select(QKEY, WEIGHT_W112, XTABLET_W112, starts_with("SMUSE"), starts_with("SOCIALNEWS2")) |>
mutate(across(everything(), ~ case_when(
is.labelled(.) ~ as.numeric(unlabelled(.)),
TRUE ~ as.numeric(.)
)))
my_W112_df |>
head(n = 25)What’s happening in this code chunk?
The line
select(QKEY, WEIGHT_W112, XTABLET_W112, starts_with("SMUSE"), starts_with("SOCIALNEWS2"))selects the variables that need for our subsequent analysis.The line
mutate(across(everything(), ~ case_when(...))):mutate(): Used to modify existing columns in a data frame.across(everything(), ~ case_when(...)): Applies the transformation to all columns in the data frame.case_when(...): A way to perform conditional transformations.is.labelled(.) ~ as.numeric(unlabelled(.)): If the column is labelled, remove labels and convert to numeric. This is important to perform on labelled data frames (like the Pew data frames which contain variable labels, value labels, and other formatting carried over from the original SPSS data frame) before analyzing the data as these formats can lead to unexpected results.TRUE ~ as.numeric(.): Otherwise, just convert the column to numeric. This handles the case where non-labelled columns are character or factor types that you want to ensure are numeric.
Please run the code chunk and then inspect the new data frame my_W112_df to verify that the code worked as intended.
Step 12
Compute the percent of users who get their news from the site (for each site)
Now that we have our data frame together, we can conduct analyses. In the graph that we replicated earlier in the semester (and is presented at the top of this activity handout), for each type of social media, the percentage of users who get their news from the site is presented. Let’s see if we can replicate those quantities for 2022.
Recall from Module 4 that the tidyverse functions, like those found in dplyr and ggplot2, work best when performed on tidy data frames. We can adhere to the tidy principles in this data frame by pivoting the SMUSE and SOCIALNEWS variables from wide (where there’s a separate column for each type of social media) to long.
Let’s start with the SMUSE items. Here, we want to have two variables to represent the SMUSE items. A first variable, which we’ll call site, that denotes which type of social media site is referred to. And, a second, which we’ll call used, that denotes whether or not the site is used by the respondent. The pivot_longer function will be used to accomplish this task.
In your Quarto analysis notebook, under the last code chunk to format the variables, create a second level header:
## Pivot the data from wide to long
Then, create a R code chunk. Inside the code chunk, copy and paste the code below. Study it carefully and read about what each step is doing below the code chunk.
my_W112_df_SMUSE <-
my_W112_df |>
select(QKEY, WEIGHT_W112, XTABLET_W112, starts_with("SMUSE")) |>
pivot_longer(cols = starts_with("SMUSE"), names_to = "SMUSE_var", values_to = "used") |>
separate(SMUSE_var, into = c("part1", "site", "part2"), sep = "_") |>
select(QKEY, WEIGHT_W112, XTABLET_W112, site, used)
my_W112_df_SMUSE |>
head(n = 100)What is happening in this code chunk?
Naming a new pivoted data frame:
- Name the pivoted data frame my_W112_df_SMUSE, and base it on my_W112_df.
Selecting relevant columns:
select(QKEY, WEIGHT_W112, XTABLET_W112, starts_with("SMUSE")):- Select the variables that we need for the pivoted data frame.
Converting data from wide to long format:
pivot_longer(cols = starts_with("SMUSE"), names_to = "SMUSE_var", values_to = "used")Use the pivot_longer() function to convert the data from wide format to long format.
Specify the columns to be pivoted (those starting with “SMUSE”).
Name the new column that will hold the original column names as SMUSE_var.
Name the new column that will hold the values from the original columns as used.
Splitting the SMUSE_var column into three parts:
separate(SMUSE_var, into = c("part1", "site", "part2"), sep = "_"):The SMUSE_var variable contains the corresponding variable name from the wide data frame. For example, if the value SMUSE_a_W112 is recorded, this refers to Facebook. The letter in between the underscores (“a” in this case) denotes the social media site. For later use, it is more convenient to extract the letter in between the underscores. We can do this with the separate() function. Click here to learn more about how this function works.
Use the separate() function to split the SMUSE_var into three parts based on underscores.
Name the new columns created from splitting as part1, site, and part2. The new variable called site will contain the letter between the underscores, and we can discard part1 and part2 since it just holds the prefix (SMUSE) and suffix (W112) respectively.
Specify the underscore (
_) as the delimiter for splitting the column.
Selecting and rearranging the final columns:
select(QKEY, WEIGHT_W112, XTABLET_W112, site, used):- Use the select() function to choose the final varaibles to keep in the data frame. Ensure only the necessary columns are included in the final data frame.
Next, we need to do the same thing for the SOCIALNEWS2 variables. Perform the same technique just described for the SMUSE variables, but now for the SOCIALNEWS2 variables. Since we’ve already captured the time stable variables (WEIGHT_W112 and XTABLET_W112) in the first pivoted data frame — we don’t need those here. Therefore, in the code just below the creation of my my_W112_df_SMUSE, create a second pivoted data frame called my_W112_df_SOCIALNEWS2 that starts by selecting QKEY and the variables that start with SOCIALNEWS2, then proceed to pivot longer (name the new variables SOCIALNEWS2_var and used_for_news) and separate the SOCIALNEWS2_var using the separate() function just as we just did for the SMUSE variables.
Do your best to get the code right, the first 100 rows of your resulting data frame should look like the one below. If you’re stuck click on the Code tabset for help.
my_W112_df_SOCIALNEWS2 <-
my_W112_df |>
select(QKEY, starts_with("SOCIALNEWS2")) |>
pivot_longer(cols = starts_with("SOCIALNEWS2"), names_to = "SOCIALNEWS2_var", values_to = "used_for_news") |>
separate(SOCIALNEWS2_var, into = c("part1", "site", "part2"), sep = "_") |>
select(QKEY, site, used_for_news)Now that we have pivoted the two variables related to social media sites used, and whether the site is used for news, we can join them together into a unified long data frame for analysis. In addition to merging them together, we need to perform a few additional tasks.
First, notice from the Questionnaire that Pinterest (item “h”) in the list of social media sites was asked for the SMUSE items, but not for the SOCIALNEW2 items. Therefore, I am going to drop rows referring to Pinterest using the filter() function.
Second, I am going to create a new variable called news_recode which records a value of 1 if the individual has internet, uses the site, and uses the site for news, and records a value of 0 if the individual has internet, uses the site, but doesn’t use the site for news. For all other instances (e.g., refusals to answer, doesn’t use the site, and/or doesn’t have internet), I will record a missing value for news_recode. NA_integer_ is used to represent missing values specifically for numeric data without decimal places. This post provides a nice overview of missing data indicators.
Third, I am going to create a new variable called site.f, which is a factor version of site that applies the corresponding site to each letter (e.g., a value of “a” corresponds to “Facebook”, a value of “b” corresponds to “YouTube”, and so forth. This information is pulled from the Questionnaire.
Carefully study each element of the code and the output to make sure you understand what’s happening. Then copy and paste this code below the second pivot_longer() call in your analysis notebook. Run the full code chunk and inspect the output to make sure the resulting data frame called my_W112_df_long matches the first 100 rows shown in the output below.
my_W112_df_long <-
my_W112_df_SMUSE |>
left_join(my_W112_df_SOCIALNEWS2, by = c("QKEY", "site")) |>
filter(site != "h") |>
mutate(news_recode = case_when(XTABLET_W112 == 2 & used == 1 & used_for_news == 1 ~ 1,
XTABLET_W112 == 2 & used == 1 & used_for_news == 2 ~ 0,
XTABLET_W112 == 2 & used == 1 & used_for_news == 99 ~ NA_integer_,
XTABLET_W112 == 2 & used == 2 ~ NA_integer_,
used == 99 ~ NA_integer_,
XTABLET_W112 == 1 ~ NA_integer_)) |>
mutate(site.f = factor(site,
levels = c("a", "b", "c", "d", "e", "f", "g", "i", "j", "k", "l"),
labels = c("Facebook", "YouTube", "Twitter", "Instagram", "Snapchat",
"WhatsApp", "LinkedIn", "TikTok", "Reddit", "Twitch", "Nextdoor")))
my_W112_df_long |>
head(n = 100)Now that we have the data frame together, we can compute the percentage of users who use the site (for each site) for news. Because we recoded the news variable, news_recode, to a binary 0/1 variable — we can now easily group by site (i.e., using group_by()), and then take the mean of news_recode using the summarize() function. This will create the proportion of users who use the site for news. To obtain the percentage, we simply multiply the proportion by 100.
You have the resources to compute these quantities. Please try to write the code yourself. You should obtain the result below. If you need help, click on the Code tabset below.
my_W112_df_long |>
group_by(site.f) |>
summarize(percent = mean(news_recode, na.rm = TRUE)*100)Let’s compare these proportions to those in the graph that we replicated earlier in the semester — focusing just on 2022 since that is the survey data that we are working with in this activity.
Notice that there are some discrepancies between our table and the graph. For example, the graph shows that 44% of Facebook users used Facebook for news regularly in 2022, while our table shows 41%. This difference arises because the graph’s estimates apply frequency weights that account for sampling procedures and nonresponse. You can read more about this process in the documentation file ATP W112 methodology.pdf. The summary below provides an overview of this information, as well as a simple example for those interested.
Important
Purpose of Survey Weights
Survey weights are an essential tool in survey research, particularly when working with data from large-scale surveys like the Pew Research Center American Trends Panel. Here’s a brief explanation about how they work and their purpose:
Survey weights are used to ensure that survey results are representative of the target population. They adjust for potential biases in the survey sample, such as:
Sampling Bias: When certain groups are overrepresented or underrepresented in the sample.
Nonresponse Bias: When individuals from certain groups are more or less likely to respond to the survey.
Post-stratification: To ensure the survey sample matches known population demographics (e.g., age, gender, race).
How Weights Work
Survey weights work by assigning different weights to survey respondents to correct for these biases. Here’s a step-by-step overview of the process:
Design Weights: These are the initial weights assigned based on the probability of selection. If some individuals had a lower probability of being selected, they get a higher weight.
Adjustment for Nonresponse: Adjustments are made to the weights to account for differences in response rates among different demographic groups.
Calibration: Weights are further adjusted to match the survey sample to known population totals (e.g., from census data) on various characteristics like age, gender, education, etc.
Example Calculation
Assume you have a sample where younger individuals are underrepresented. Here’s how weights might be applied:
Initial Probability Weights:
Suppose individuals aged 18-24 have a selection probability of 0.2, and those aged 25-64 have a probability of 0.5.
Initial weights would be inversely proportional to these probabilities, so 18-24 year-olds get a weight of 5 (1/0.2) and 25-64 year-olds get a weight of 2 (1/0.5).
Nonresponse Adjustment:
If the response rate among 18-24 year-olds is 60%, the weight is adjusted to 5 / 0.6 ≈ 8.33.
If the response rate among 25-64 year-olds is 70%, the weight is adjusted to 2 / 0.7 ≈ 2.86.
Calibration:
- The final step involves adjusting these weights to match the known distribution in the population. If the census data shows 18-24 year-olds should represent 15% of the population and 25-64 year-olds 70%, the weights are scaled so that the weighted proportions match these population targets.
Applying Weights in Analysis
In practice, survey weights are applied in the analysis phase to ensure that the estimates (e.g., means, proportions, regression coefficients) are representative of the target population. In statistical software like R, this is typically done by specifying the weights when fitting models or calculating summary statistics. You’ll see an example of this shortly.
The survey package provides a method for accounting for these weights. This tutorial by the author offers additional help for using the package. The code below provides the approach needed to obtain the right estimates for this problem. Take a look at the code, and read through the description of each step below.
# Create a survey design object
my_design <- svydesign(
id = ~1, # Specifies that there is no clustering in the survey design
weights = ~WEIGHT_W112, # Specifies the column containing the survey weights
data = my_W112_df_long # Specifies the data frame containing the survey data
)
# Calculate the weighted summary by group
weighted_summary <-
weighted_summary <- svyby(
formula = ~news_recode, # The variable to summarize (news_recode)
by = ~site.f, # The grouping variable (site.f, representing different social media sites)
design = my_design, # The survey design object created with svydesign
FUN = svymean, # The function to apply for each group (svymean calculates the weighted mean)
na.rm = TRUE # Remove missing values before calculation
) |>
as.data.frame()
# Convert the result to a data frame and calculate the percentage
weighted_summary_df <-
weighted_summary |>
mutate(percent = news_recode * 100) |>
select(site.f, percent)
# View the result
weighted_summary_dfWhat’s happening in this code chunk?
svydesign(id = ~1, weights = ~WEIGHT_W112, data = my_W112_df_long):svydesign(): This function from th survey package is used to create a survey design object (which we name my_design). A survey design object is a structured representation of survey data that incorporates information about the survey’s sampling design, including weights, clustering, and stratification, allowing for accurate and representative weighted analyses of the data.
id = ~1: Specifies that there is no clustering in the data (each observation is its own cluster). The tilde~is used to indicate a formula in R. If in the survey, for example, respondents were nested in some relevant structure — like households or schools or businesses — then clustering could be accounted for here.weights = ~WEIGHT_W112: Specifies the column that contains the survey weights. In this case, WEIGHT_W112 is the column with the weights.data = my_W112_df_long: The data frame that contains the data.
svyby(formula = ~news_recode, by = ~site.f, design = my_design, svymean, na.rm = TRUE):svyby(): This function calculates summary statistics by groups, taking the survey design into account.
formula = ~news_recode: Specifies the variable to be summarized.by = ~site.f: Specifies the grouping variable. Here, site.f is the factor variable indicating different social media sites.design = my_design: The survey design object created first is referred to here.FUN = svymean: The function used to calculate the mean for each group.na.rm = TRUE: Indicates how to handle missing data.|> as.data.frame(): Converts the result to a data frame for easier manipulation.
weighted_summary_df <- weighted_summary |> mutate(percent = news_recode * 100) |> select(site.f, percent):- This converts the weighted mean of news_recode computed in the
FUN = svymeanstep above, which is in the metric of a proportion, to a percentage.
- This converts the weighted mean of news_recode computed in the
Important
When creating the survey design object using the svydesign() function, it is important to include all rows of data, even those with missing values. This approach ensures that the survey design object accurately reflects the entire data frame and retains the structure of the survey sample. Removing cases with missing data at this stage (e.g., people without internet or people who don’t use Facebook or people who refused to answer a question) could bias the results and distort the representativeness of the survey. Handling missing data should be done during the analysis phase, where specified mathematical functions like FUN = svymean can be used with the na.rm = TRUE argument to exclude missing values appropriately.
Once you have a handle on what’s happening, in your Quarto analysis notebook, under the last code chunk to pivot the variables, create a second level header:
## Estimate the percentage of users accounting for survey weights
Insert a code chunk, then copy and paste the code in the code chunk above into your analysis notebook. Run the code chunk to ensure you obtain the same results. Verify that these weighted percentages match those for 2022 in the Pew Research Center graph that we replicated earlier in the semester.
Step 13
As a final step, please use the weighted results (i.e., weighted_summary_df) to create a graph that depicts the weighted percentages. An example graph is shown below. Give it your best shot to write the code yourself, if you’re stuck, click on the Code tabset for help.
In your Quarto analysis notebook, under the last code chunk to create the weighted table of results, create a second level header:
## Create a graph of the results
Insert a code chunk, then create a graph of the results. You can be creative and create whatever type of plot you see fit to display the 2022 data.
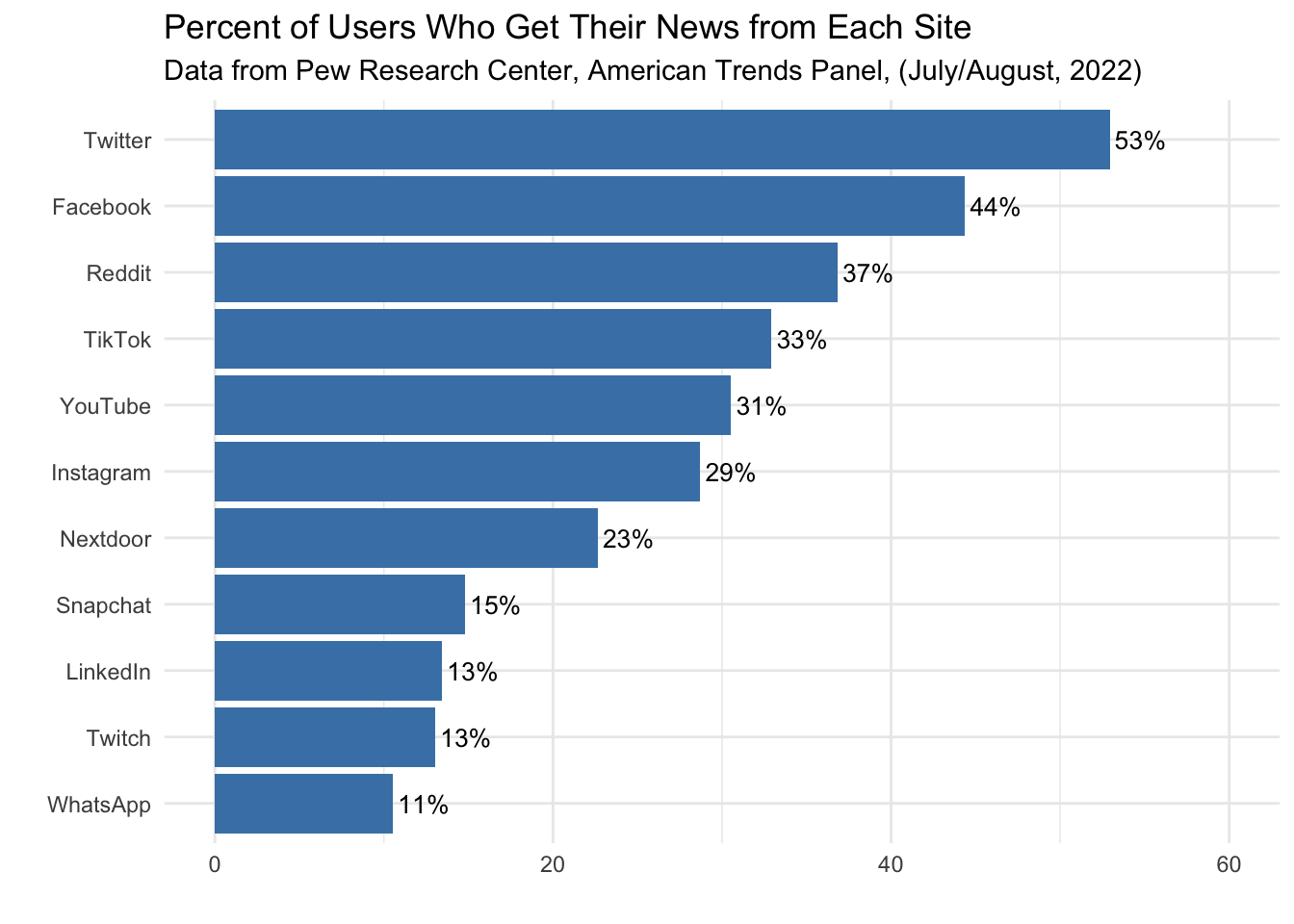
weighted_summary_df |>
ggplot(mapping = aes(x = percent, y = reorder(site.f, percent))) +
geom_col(fill = "steelblue") +
geom_text(mapping = aes(label = sprintf("%.0f%%", percent)),
hjust = -0.1,
size = 3.5) +
labs(title = "Percent of Users Who Get Their News from Each Site",
subtitle = "Data from Pew Research Center, American Trends Panel, (July/August, 2022)",
x = "Percent",
y = "Site") +
theme_minimal() +
theme(axis.text.y = element_text(size = 10),
axis.title.y = element_blank()) +
xlim(0, 60)Step 14
Finalize and submit.
Now that you’ve completed all tasks, to help ensure reproducibility, click the down arrow beside the Run button toward the top of your screen then click Restart R and Clear Output. Scroll through your notebook and see that all of the output is now gone. Now, click the down arrow beside the Run button again, then click Restart R and Run All Chunks. Scroll through the file and make sure that everything ran as you would expect. You will find a red bar on the side of a code chunk if an error has occurred. Taking this step ensures that all code chunks are running from top to bottom, in the intended sequence, and producing output that will be reproduced the next time you work on this project.
Now that all code chunks are working as you’d like, click Render. This will create an .html output of your report. Scroll through to make sure everything is correct. The .html output file will be saved along side the corresponding .qmd notebook file.
Follow the directions on Canvas for the Apply and Practice Assignment entitled “Pew Project Apply and Practice Activity” to get credit for completing this assignment.