Create and render a basic Quarto analysis notebook
Write R code using core functions and packages
Import data using reproducible file paths with the here() function
Explore data using functions like glimpse() and skim()
Organize files in a project folder structure with data, programs, and documentation
Apply principles of a reproducible workflow, including rendering reports and documenting your code
Introduction to the Tools
R, RStudio, and the Posit Cloud
We will use R for data science in this course. R is a powerful, open-source language and environment for statistical computing and graphics. It consists of a core software program and thousands of user-created packages that extend its capabilities.
To access R, we will use RStudio, a free integrated development environment (IDE) that makes it easier to write and run R code. Both R and RStudio are available for Windows and Mac, and while you can install them on your own computer, we will use a cloud-based option instead.
For this course, you’ll use Posit Cloud — a remote server that runs R and RStudio in your web browser. This approach removes the need to install software on your personal computer and allows you to start coding quickly and easily.
Later in the semester, you’ll have the option to install R and RStudio on your own machine and practice transferring a project from Posit Cloud to your local setup. The experience of using RStudio on the Cloud is nearly identical to using it locally. The main difference is how files are managed: on Posit Cloud, you upload files to folders within your project workspace; on your local computer, you’ll manage files using tools like Finder (on a Mac) or File Explorer (on a PC).
Accessing the Posit Cloud
To begin, please create a Posit Cloud account at this website, click on GET STARTED. There is a free option that you can use. This includes 25 hours to work on the server per month. Depending on your workflow, this may be enough. However, if it’s not, at anytime, you can add an additional 50 hours per month for $5 per month using the Student Plan. If you choose this option, you will pay Posit Cloud directly for this plan.
Importing the materials
Once you have a Posit Cloud account set up, please copy the foundations project from my Posit Cloud account to your account. Please follow these directions to accomplish this task:
Click on this link to access the materials on my Posit Cloud account — they’re stored in a project called foundations. Clicking on the project should launch Posit Cloud and open the foundations project in your account.
You should see that the project is a TEMPORARY COPY (there will be a red warning at the top of your window). YOU MUST now save your own permanent copy.
Click on Save a Permanent Copy at the top of the window.
Now, click back on Your Workspace (on the top left side of the window). You should now see that foundations is a project owned by you — and listed under Your Projects.
It’s very important that you perform Steps 1 through 4 above ONLY ONCE. Please don’t download the foundations project from my account more than once — from here on out — make sure that you are always working in your own foundations project. Your name should be in the upper right hand corner of the screen anytime you log into the Posit Cloud.
Setting up RStudio
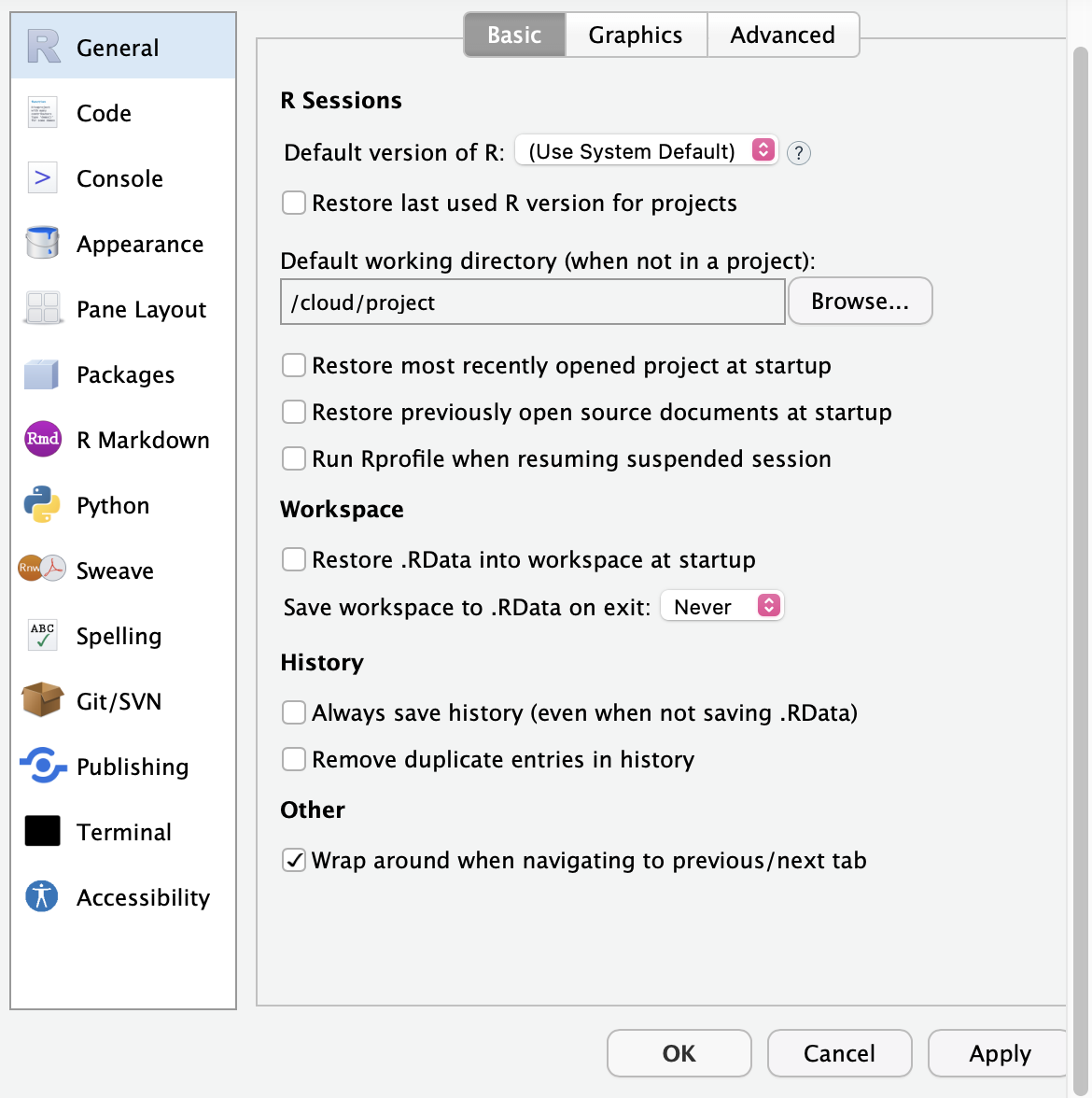
Next, I’d like for you to change the global settings for your project so that we’re all working under the same settings. THIS IS VERY IMPORTANT! Enter your foundations project by clicking on it. Please click on Tools and then choose Global Options. This will bring up a dialog box.
In the dialog box, please do the following:
Uncheck all boxes that are checked except the very last one (i.e., “Wrap around when navigating to previous/next tab”).
Under the heading Workspace change the option “Save workspace to .RData on exit” to Never.
When done, click Apply and then OK.
Your dialog box should look like this:
Important
Take a screen shot of the Global Options dialog box. Here are some directions for taking a screen shot on a Mac and on a Windows machine. You will upload this to Canvas as part of your first Apply and Practice Assignment, directions are provided on Canvas (see Set Up RStudio Apply and Practice Activity in Assignments in our Canvas course).
Additionally, please make your copy of the foundations project public so that the instructors can view your work and offer help when needed. To do this, click on the Gear icon (it’s toward the top of your RStudio screen — just to the right of the RAM icon). Click Access, then in the drop down menu choose All Posit Cloud Users.
Important
Copy the url for your project and submit it to the Apply and Practice Activity called “Make Your Foundations Project Public Apply and Practice Activity” on Canvas.
Now that we’ve logged on to the Posit Cloud, opened up our RStudio project, and configured our project — the fun can begin! Let’s begin working in our session.
Explore the Project
When you first open your project, you are going to see a screen that looks like this:
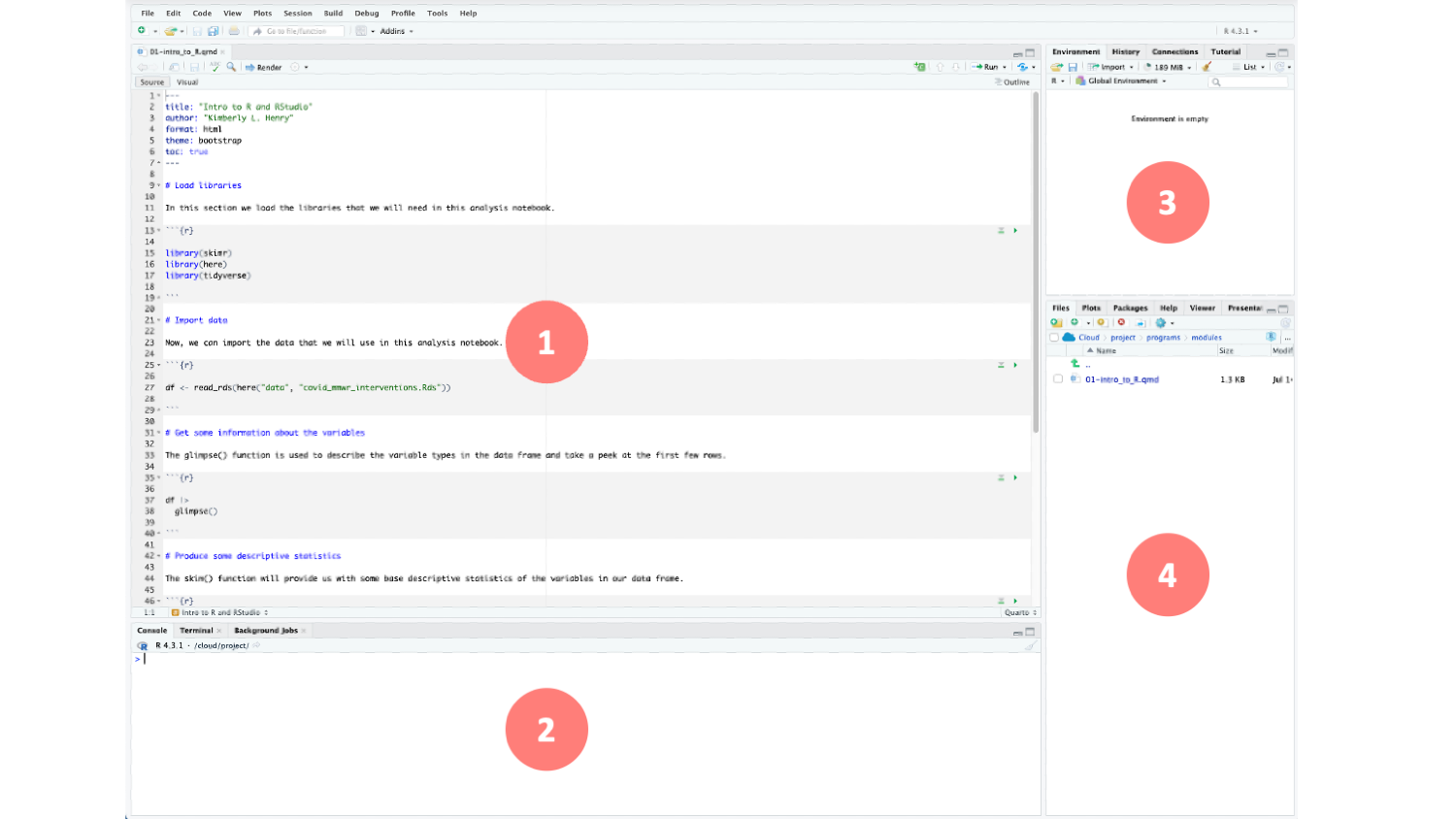
Before explaining each of these panes, let’s open up the Quarto analysis notebook for this Module. In this course, we will use Quarto analysis notebooks to wrangle, plot, and analyze data. Once our analysis notebook is complete, we will render it to a beautiful and reproducible report that displays all of our work and allows us to communicate our findings to others. Later in the course, you’ll see that we can create many different types of Quarto documents — for example, academic papers, presentation slides, blogs, books and websites. I created the Foundations in Data Science website that you’re browsing now using Quarto.
Artwork by @allison_horst
Let’s open the 01-intro_to_R.qmd file (the qmd extension stands for Quarto Markdown). Be sure that you are in your personal foundations project, then do the following: In the lower right quadrant of your screen, click on the programs folder, then click on the module_programs folder. Inside the module_programs folder is a file called 01-intro_to_R.qmd. Click on the file and it will open. Your screen should now look like this:
The RStudio interface is divided into four main panes, as shown above. Each pane provides different functions to help you work with R more efficiently.
Source (Top-Left Pane): This is the script editor pane where you write and edit your documents. The editor provides features like syntax highlighting, code completion, and tabbed editing. You can run your code line by line, as a section, or as a whole script (you’ll see examples of these options later on in this Module). Mostly, we will work in this pane.
Console (Bottom-Left Pane): This is the interactive R shell1 where you can directly type and execute R commands. The console displays output from commands you run, and is also where error and warning messages appear. When you run code from the Source pane, the code and its output appear here in the Console. We won’t actually do much in this pane as we’ll primarily look at output in the analysis notebook itself (i.e., in the Source pane).
Environment (Top-Right Pane): This pane has several tabs. The Environment tab is what we’ll primarily use — it shows a list of all the objects (like variables, data frames, functions, etc.) currently in your workspace.
Files (Bottom-Right Pane): This pane has multiple tabs. The Files tab displays your file directory, and allows you to manage and load files. A directory on a computer is a file system structure that contains and organizes files and other directories/subdirectories. Directories are often referred to as “folders” in graphical user interfaces. We’ll use the files tab of this pane most often. Other useful tabs in this pane include the Packages tab — which shows all installed R packages, and allows you to install, load, and unload packages. The Help tab displays documentation for R functions and packages, and provides access to R help resources. When you click on the Help tab, you’ll see a search box with a magnifying glass. You can search for information about R packages, functions, etc. here.
These panes can be customized, meaning you can change their sizes or even move them around based on your preference. To do this, click Tools in the menu, then choose Global Options. Next choose Pane Layout and indicate how you’d like the panes to be displayed. In the main RStudio window, you can also click on and drag the dividers between the panes to make them larger or smaller.
Organization of project files
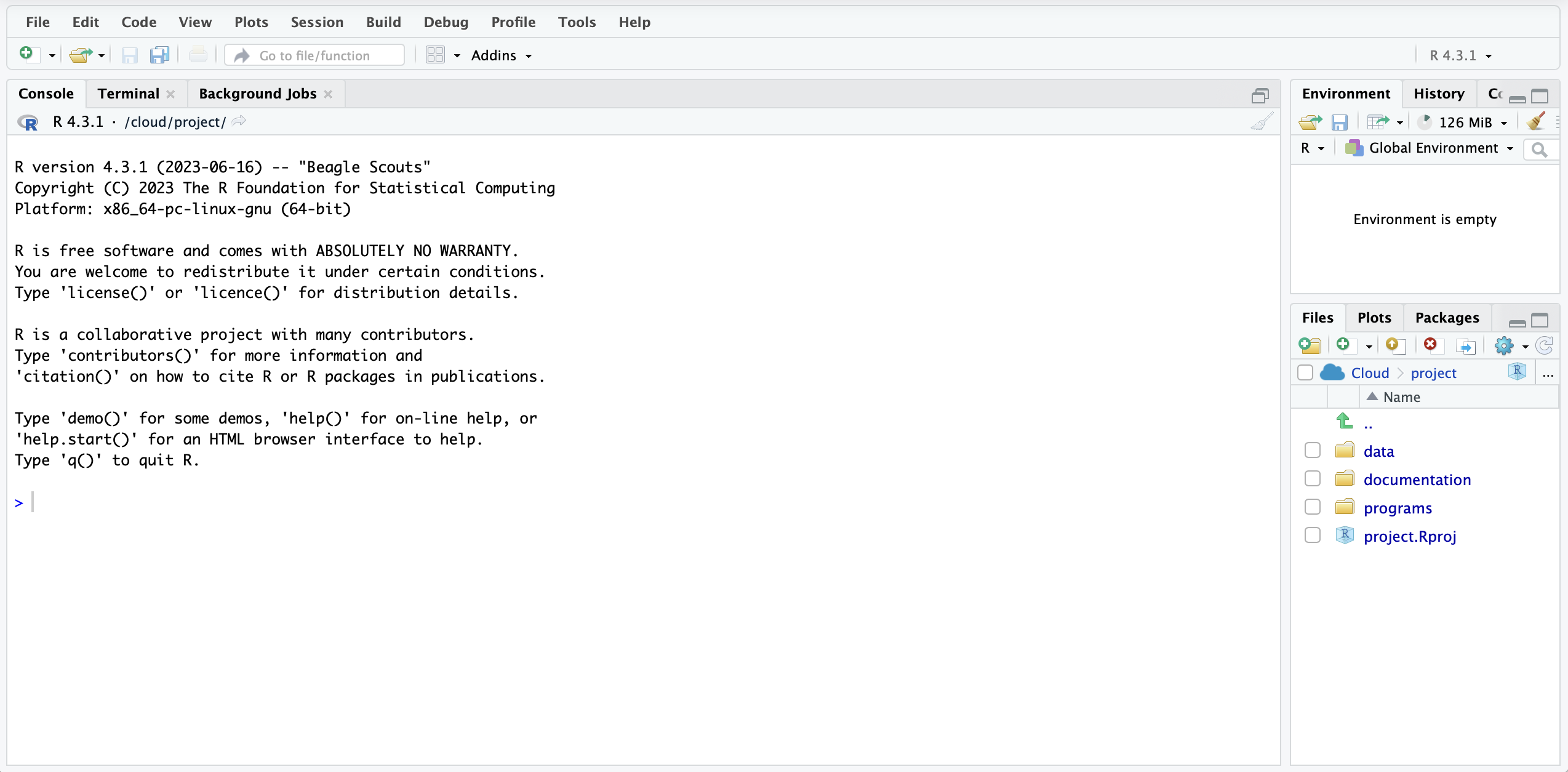
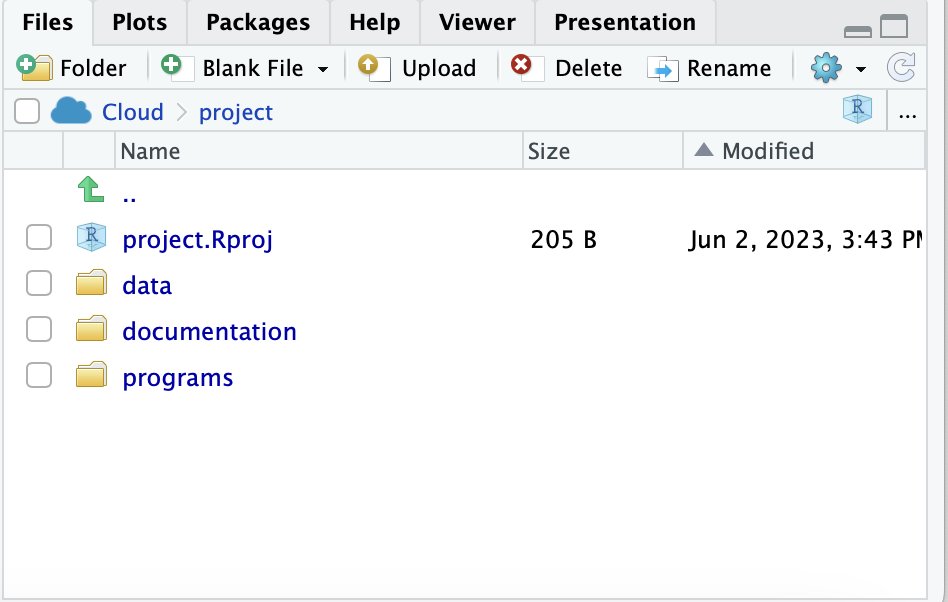
Notice the bottom right section of the window titled Files. If it’s not already selected, click on project in the bread crumbs, so that the address is Cloud > project. Here, all of the files that are part of the foundations project are listed. Data science requires excellent organization, and organizing files is a big part of this process. I have created three folders to organize the materials, there is a screenshot of the files below.
The first is data. Inside this folder are the data frames needed for the project. Data frames are rectangular spreadsheets in which the rows correspond to observations and the columns correspond to variables that describe the observations. Other terms for data frames are data sets, data files, and spreadsheets.
The second is documentation. Inside this folder are all of the documents that are needed to describe the project. For a research study, this might include descriptions of the study design or important papers that describe study measures. For our class project, this includes additional materials that you will need while using RStudio for this course.
The third folder is programs. Inside this folder are the Quarto analysis notebooks that you can use to study and practice using the code chunks in the Modules for this course and for the Apply and Practice Activities that we will do together.
Elements of a Quarto Analysis Notebook
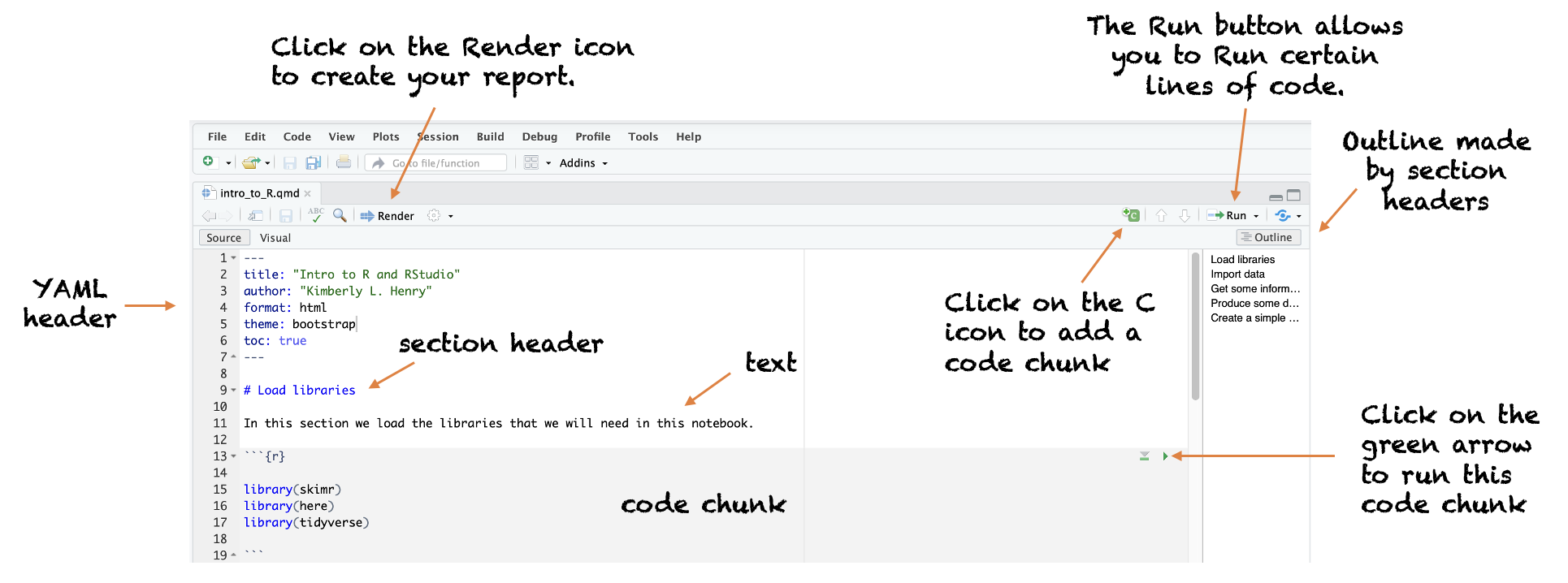
Let’s break down the elements of the code in the 01-intro_to_R.qmd file (i.e., a Quarto analysis notebook). The image below depicts the key elements — and in this section we’ll learn about each one.
YAML header
The YAML header2 is the section located at the very top of a Quarto document, enclosed between two sets of three dashes. It serves as the configuration instructions for the document. Every Quarto document should include this section, and it is mandatory for it to begin and end with the three dashes.
Section header
Take a look at the next section below the YAML header which starts with a single hash symbol and then a section header called Load libraries
The line that begins with a hash symbol is called a section header. These headers work like an indented outline that you’d create for a Microsoft Word report.
One hash symbol: # section header title — denotes a first level header,
Two hash symbols: ## section header title — denotes a second level header,
and so on…
It’s smart to label each section with informative section header titles, this will help you to find sections easily when your notebook becomes very long. And, these headers can be used to build a table of contents (like the scrolling table of contents that appears on the right side of the webpage you are reading now). This information will be populated in the Outline section. You can toggle the Outline on and off by clicking on Outline. You can use the Outline to move quickly to a certain part of your analysis notebook. For example, in the 01-intro_to_R.qmd file, click on Outline to show the outline, then click on Create a simple plot to navigate quickly to the last section of the notebook that creates a plot.
Text
Just below the Load libraries section header you will find plain text: “In this section…”
When you write plain text in the white part of the analysis notebook, this will appear in your outputted report (also called a rendered report or a knitted report) as plain text. This is a good place to explain what you’re doing in each section, or to provide interpretations of your output.
Code chunk
Just below the text, you’ll see a gray box — this is called a code chunk. Code chunks are where we write our R code to wrangle, visualize, and analyze data. In Quarto, a code chunk begins with three backticks followed by {r} in curly braces, like this:
Notice that it also ends in three backticks. Without both the opening and closing backticks, RStudio and Quarto won’t recognize it as a complete code chunk, and you won’t be able to run the code chunk and your document may not render correctly.
We write our R code to wrangle, visualize and analyze data inside these code chunks. In this first code chunk, we are simply loading a few packages that we will use in this session.
R functions are stored in packages. When a package is loaded into a session, it’s contents are available for use. Packages add to the capability of R by enhancing existing base R functionalities, and in many cases adding brand new capabilities.
To use a package you must first install it. This is done using the install.packages() function — I already loaded all of the packages we will need for the start of the course — therefore, this step is not necessary for you at this time.
Once a package is installed in your system, when you want to use it in a particular session, you call it into the session by typing library(package_name), where package_name is replaced with the package you want to use.
So, what exactly are functions? A function is a set of code used to carry out a specified task. A function has a name, is followed by parentheses (i.e., function_name()), and inside the parentheses are any needed arguments for the function. Arguments are the directions to tell the function what to do. Sometimes there are no arguments needed because the function does one task by default, sometimes the arguments are very simple, and sometimes they are more complex. We’ll start with simple arguments. For example, in the example code chunk, library() is a function. It’s purpose is to carry out the task of loading a package into memory to use in a session. There is just one argument to this function, and that is to indicate which package to load.
The first library function loads the skimr package, which we will use to obtain descriptive statistics.
The second library function loads the here package, which we will use to tell R where to look for files (e.g., the directory where our data are found).
The third library function loads the tidyverse package. The tidyverse is actually an umbrella package for a set of core packages that we will use to wrangle, visualize and analyze data (e.g., dplyr for data wrangling, ggplot2 for data visualization, etc.).
Once we click the green arrow to run the code chunk, all of these packages will be loaded and ready for us to use their functions. As an example, skimr is a package that we will use to describe data. We can load it into the session by running the code library(skimr). Once loaded, we can use it’s functions. For instance, skim() is a function that provides basic descriptive statistics for the variables in a data frame. So, if we want to get descriptive statistics for all of the variables in a data frame called mtcars (which is a built in example data frame in R), we could write the following code, which when executed, produces the output below the code.
library(skimr)skim(mtcars)
Data summary
Name
mtcars
Number of rows
32
Number of columns
11
_______________________
Column type frequency:
numeric
11
________________________
Group variables
None
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
mpg
0
1
20.09
6.03
10.40
15.43
19.20
22.80
33.90
▃▇▅▁▂
cyl
0
1
6.19
1.79
4.00
4.00
6.00
8.00
8.00
▆▁▃▁▇
disp
0
1
230.72
123.94
71.10
120.83
196.30
326.00
472.00
▇▃▃▃▂
hp
0
1
146.69
68.56
52.00
96.50
123.00
180.00
335.00
▇▇▆▃▁
drat
0
1
3.60
0.53
2.76
3.08
3.70
3.92
4.93
▇▃▇▅▁
wt
0
1
3.22
0.98
1.51
2.58
3.33
3.61
5.42
▃▃▇▁▂
qsec
0
1
17.85
1.79
14.50
16.89
17.71
18.90
22.90
▃▇▇▂▁
vs
0
1
0.44
0.50
0.00
0.00
0.00
1.00
1.00
▇▁▁▁▆
am
0
1
0.41
0.50
0.00
0.00
0.00
1.00
1.00
▇▁▁▁▆
gear
0
1
3.69
0.74
3.00
3.00
4.00
4.00
5.00
▇▁▆▁▂
carb
0
1
2.81
1.62
1.00
2.00
2.00
4.00
8.00
▇▂▅▁▁
In most analyses, you’ll start your notebook with a code chunk at the top that loads all the packages you’ll need. This is the standard workflow: load your packages once, then use their functions throughout the rest of your notebook. Just remember — the code won’t take effect until you run the chunk that loads the packages. Simply typing the code isn’t enough; you need to execute it (e.g., by clicking the “Run” button) to actually load the packages into your workspace.
I want to make you aware of another method for using a function from a package, as you will see this technique from time to time. Rather than loading a package in the session using the library() function, instead you can use the double colon operator — where for a package called pkg, and a function called fnct — one writes pkg::fnct(). For example, to use the skim() function in the skimr package, we could equivalently write and execute:
skimr::skim(mtcars)
This is useful if you’re only going to use the function once or twice in a session3. It becomes monotonous to use the double colon operator over and over. Therefore, for commonly used packages, it’s efficient to load them into the session using the library() function. That way, you can set and forget.
In this course, at first we’ll rely on code chunks that I have created. Soon, however, you will create your own code chunks. To create a new code chunk, put your cursor where you want the code chunk to go, then click on the green C button (with a plus sign) toward the top section of the RStudio window. To execute (i.e., run or submit) the code in the code chunk, press the green side arrow at the top right of the code chunk. If you want to delete a code chunk, just highlight it (from before the first set of backticks to after the second set of backticks, then hit delete).
For a quick demonstration of creating, and then deleting, a code chunk, see the video below.
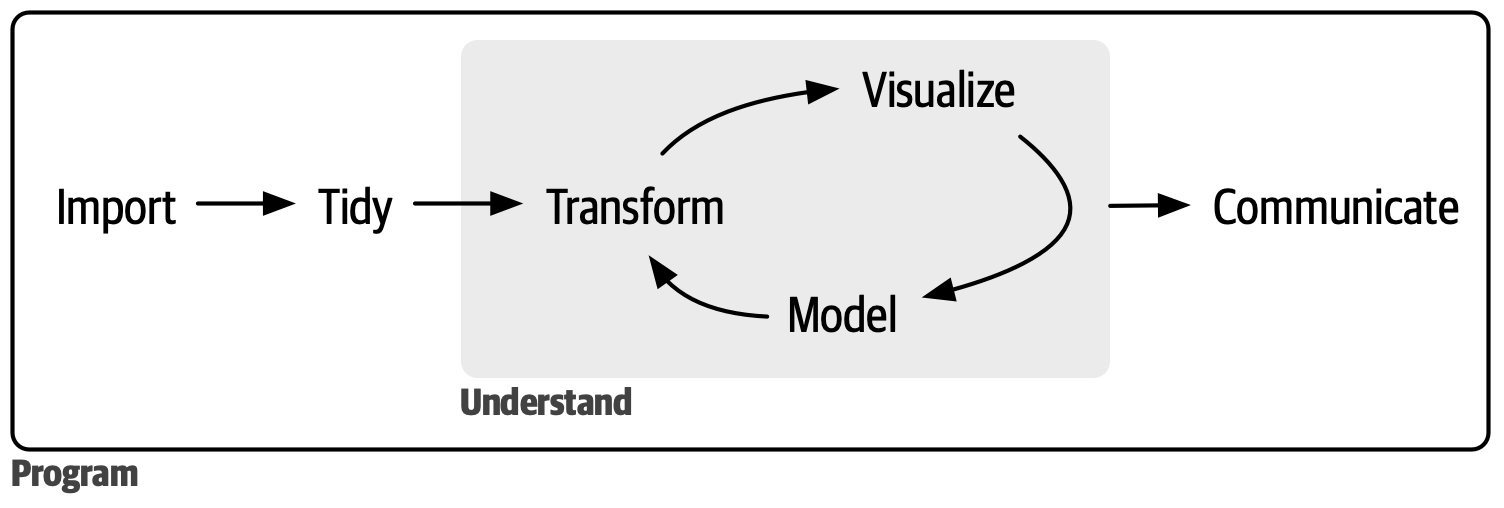
The Data Analysis Pipeline with R
Throughout this course, we’ll use the data science process recommended by Hadley Wickham and colleagues in R for Data Science. The process is depicted in the figure below.
First, you need to import your data into R, which usually means transferring data stored in a file, database, or web API and loading it into an R data frame. Without getting your data into R, you can’t carry out data science work.
Once your data is imported, it’s beneficial to tidy it. Simply put, in tidy data, each column represents a variable, and each row corresponds to an observation. Tidy data is vital as its uniform structure allows you to concentrate on exploring the data rather than struggling to adjust the data to fit different functions. We’ll practice these steps in the Data Wrangling Module.
After tidying your data, a usual next step is to transform it. Transformation involves tasks such as subsetting the data (e.g., picking just a few variables or choosing certain types of cases — for example, teenagers or people who live in the U.S.), generating new variables from existing ones (like calculating a scale score for a set of personality items), and calculating a set of summary statistics (like counts or averages). Both tidying and transforming are often called wrangling, as getting your data into a user-friendly form can feel like a struggle! We’ll practice these steps in the Data Wrangling Module.
Once your data is tidy and has the variables you need, there are two main methods of generating insights: visualization and modeling. Both have their own strengths and weaknesses, and you will usually find yourself oscillating between the two during any real data analysis. Visualization is primarily a human-centered process. A good visualization can reveal unexpected insights or trigger new questions about the data. It may also suggest that you might be asking the wrong questions or need to collect different types of data. We’ll practice these steps in the Data Visualization Module. Models, on the other hand, complement visualization. Once your questions are adequately defined, a model can be used to answer them. We’ll learn about several foundational models in this course — including models for prediction of an outcome, models for examining the effects of treatments in randomized experiments, and models that help us understand the effect of a variable of interest on an important outcome while holding constant other control variables.
The final stage of data science is communication, a crucial aspect of any data analysis project. Regardless of the insights gained from your models and visualizations, they’re useless unless you can effectively communicate your findings to others. In this course, we’ll use R, RStudio and Quarto tools to effectively communicate our findings using a variety of methods (e.g., reports, scientific papers, presentations, etc.).
Programming underlies all these tools. Programming is a common tool that you’ll use in nearly every part of a data science project. You don’t have to be a programming expert to be a successful data scientist. Still, enhancing your programming skills is beneficial as it allows you to automate regular tasks and tackle new problems more efficiently.
You’ll use these tools in every data science project, and they will serve as a strong foundation that will allow you to delve into more advanced techniques down the road.
Walk through the Module 1 Analysis Notebook
Let’s use these tools to explore our first simple analysis notebook — the one for this Module — it’s called 01-intro_to_R.qmd in the module_programs folder in the programs folder of the foundations project (the file that you should already have open). Please follow along in your analysis notebook as we explore each section.
Before we begin, I want to emphasize that R is case sensitive. Moreover, all of the code that we write needs to be precise, otherwise R won’t understand our instructions.
Load libraries
The first section of the analysis notebook loads the various packages that we need to do the work in the Quarto analysis notebook. To begin, we must click the green arrow on the upper right of the code chunk to load the packages needed for this session. Running this code chunk will make these three packages available to us.
Tip
Here are a few alternative ways to run code in a Quarto analysis notebook that you can explore if you like:
Note that if you want to run just some of the lines of code, and not the whole code chunk, you can put your cursor on the line (or highlight the lines) then click Run (at the top of the R studio pane) and choose Run Selected Line(s).
You can also use built in keyboard short cuts. Pressing Cmd/Ctrl + Enter4 will run the line of code where your cursor is placed. It will also move the cursor to the following line, and you can run through each line by repeatedly pressing Cmd/Ctrl + Enter.
Instead of running the code line by line you can use the keyboard short cut Cmd/Ctrl + Shift + Enter to run the whole code chunk (i.e., the code chunk in which your cursor is placed).
library(skimr)library(here)library(tidyverse)
Import data
Now, let’s import a data frame. The code chunk under the section header labeled # Import data imports a data file called covid_mmwr_interventions.Rds (a file with a Rds extension is a R data frame).
First, <- in R is called an assignment operator, it assigns an object to a name. An object is a data structure that stores values or data. It can be a variable in a data frame, a vector5, a matrix6, a data frame, or a list7. Objects are used to store and manipulate data in R, and they can be assigned values, modified, and accessed through their names. In this example, the object is our data frame, and the name is df.
You could assign any name you like. For example, by changing
df <-
to
my_data <-
you would call your data frame my_data instead of df. Note that if you made this change, then in the remainder of the code, you’d need to change instances of df to my_data since the name of the data frame object changed.
Notice that there are two functions being used in the remainder of the code: here() and read_rds().
here() tells R where to find the data.
read_rds() imports a .Rds data frame.
Notice that they are embedded in one another, that is, here() is acting as an argument to read_rds().
Let’s start with here("data", "covid_mmwr_interventions.Rds"). The arguments to here() are the directory where the data exist (data in our example), and the name of the data frame in the directory (covid_mmwr_interventions.Rds in our example). That is, inside the data folder, there is a data frame of this name. You can explore this in the “Files” tab in the lower right quadrant of your RStudio session in the Posit Cloud.
The here package provides a convenient way to refer to files and directories within your project. It automatically constructs file paths relative to the top-level directory, often called the root directory, which is the main folder that contains all the files and subfolders for your project. In the Posit Cloud, this root directory is your project folder.
When you call here(), it searches for the root directory. Once it is found, here() uses this root directory as a reference point for constructing file paths relative to your project.
For example, in the foundations project, here() establishes the root directory8 as our project folder. Inside this project there is a folder called data — inside that data folder is the covid_mmwr_interventions.Rds data frame. Therefore, the here() function is telling R to find this data frame in the data folder of the project.
This approach makes your code more portable because you don’t have to hard code absolute paths. For example, if in referring to your data frame, you had a path like this:
Then, when you send your project folder to a colleague, they’d have to change these hard coded absolute paths because, of course, the path to the data would be different on their computer (no one except me probably has a folder called /Users/kimhenry on their computer).
Delightfully, the here package solves these issues. You could simply share your project folder with anyone else — and all of the code would work seamlessly for them without having to modify directories and paths. In other words, the here package handles the path resolution for you, ensuring that your code works consistently regardless of where your project is located on different machines or operating systems. Hooray!!
Now consider the read_rds() function — this simply tells R to read in the covid_mmwr_interventions.Rds data frame that lives in the data folder (thanks to here) as a Rds data file type. That’s the native data file type for R.
In summary, this set of code defines an object named df. It first tells R that we’re going to import a Rds data frame, then identifies the location of the data frame to be imported, using here().
Once you run this code chunk — in the upper right section of your RStudio screen, under the Environment tab — you will see a file called df. Click on it and it will open up. It’s a data frame that includes all of the variables and values for this data frame. Take a look at the variables (columns) and entries — what do you think the variables represent (i.e., the columns)? What do the rows represent? After viewing, click the \(\times\) button beside the df tab to close it.
Examine the structure of the data frame
Now that we have our data frame imported into our session, we can use it. The next code chunk in your analysis notebook is labeled with the section header # Get some information about the variables.
df |>glimpse()
Notice that the first part of the code mentions the data frame that we just created (df), and is followed by a space and then the symbol |>. This symbol is called a pipe operator. Essentially, it takes the set of instructions on the left side of the operator (a data frame, df, in our case) and feeds it to the set of instructions on the right side of the operator (the glimpse() function in our case). When you see the pipe operator, think to yourself “and then” (I’ll give you some examples below). In other words, the pipe operator allows you to pass the output of one function directly into another function as an argument, effectively chaining multiple operations in a linear and intuitive sequence. Always include the pipe operator at the end of the first set of instructions, then return to a new line (RStudio will automatically indent for you to keep your code clean and easy to read), and then include the next set of instructions. Note that the symbol %>% can also work as the pipe operator provided you have the tidyverse loaded.
The glimpse() function is used to describe the variable types in the data frame and take a peek at the first few rows. It’s a simple function that requires no arguments. You can read the pipeline as saying, “take the df data frame and then feed it to the glimpse() function to take a look at the data.”
Once the code is executed, you’ll see the following output:
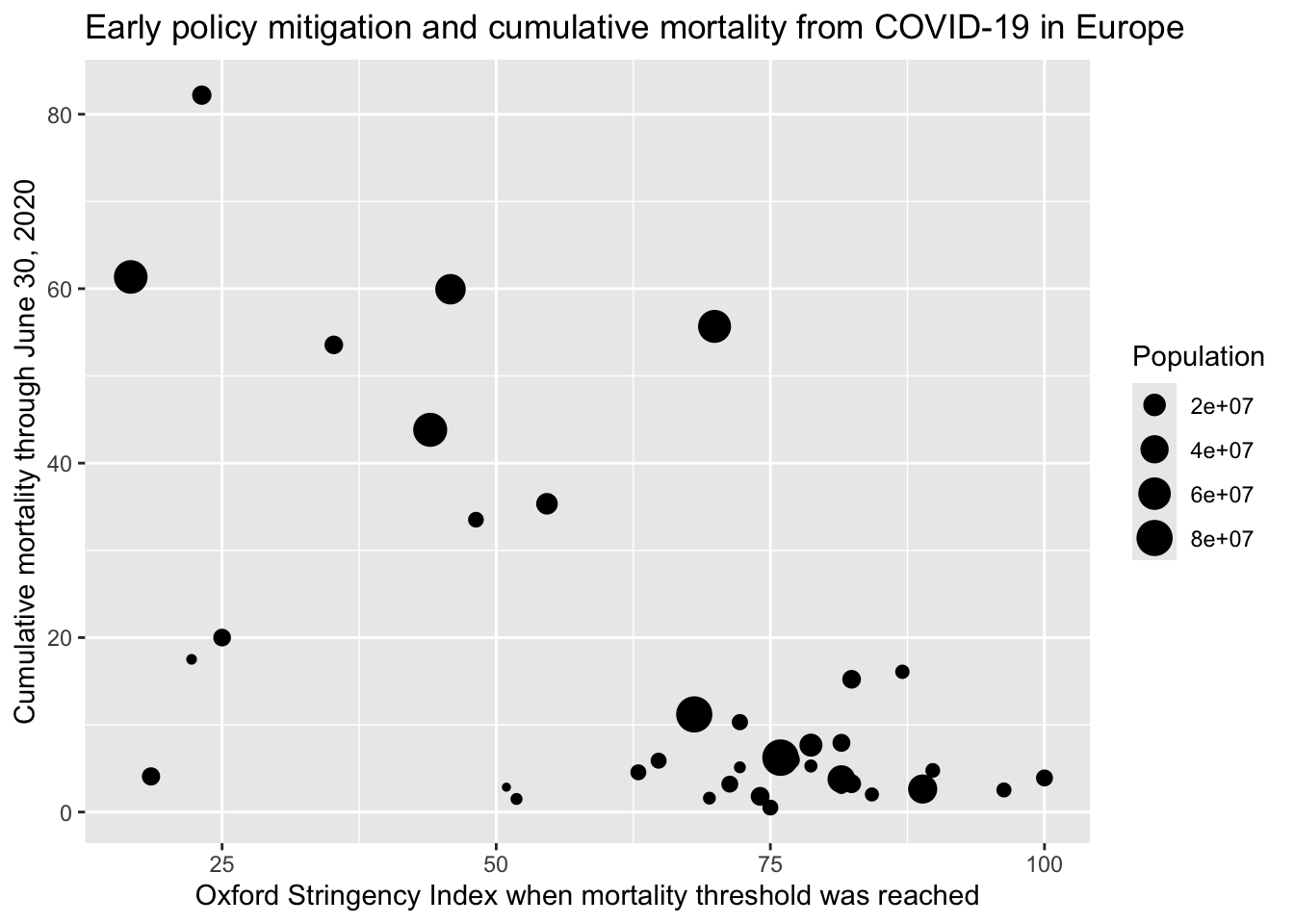
We’ll use the covid_mmwr_interventions.Rds data in Module 3 and will learn about each variable then. But, for now, notice that glimpse() tells us that there are 37 rows of data (these correspond to 37 European countries), and 6 columns (i.e., 6 variables).
Two of the variables, country and country_code, are character variables (denoted as <chr>). Character variables are a string of letters, numbers, and/or symbols).
Three of the variables are doubles (denoted as <dbl>, i.e., a double is a numeric variable that can have places after the decimal point9).
One of the variables, date_death_threshold, is a date (denoted as <date>).
This data frame is a good illustration of the different types of variables common in data science projects. We’ll work with a wide variety of data types in this course. Other common types that you’ll see are integers (denoted at <int> by R) and factors (denoted as <fct> by R). In R, integers are a data type used to represent a variable characterized by whole numbers without decimal places. Factors10 are a special type of character variable that have some distinct benefits for data visualization and analysis — we’ll see some of these benefits later in the course.
Descriptive statistics
The next code chunk in your analysis notebook starts with the section header: # Produce some descriptive statistics.
In this code chunk, we use the skim() function from the skim package to request descriptive statistics for all of the variables in the data frame. Read the pipeline as saying, “take the df data frame and then feed it to the skim() function. This function gives us quite a bit more information over glimpse(). Please carefully read through all of the available output to familiarize yourself with the information provided by skim().
df |>skim()
Data summary
Name
df
Number of rows
37
Number of columns
6
_______________________
Column type frequency:
character
2
Date
1
numeric
3
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
country
0
1
5
22
0
37
0
country_code
0
1
3
3
0
37
0
Variable type: Date
skim_variable
n_missing
complete_rate
min
max
median
n_unique
date_death_threshold
0
1
2020-03-02
2020-04-18
2020-03-23
22
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
population_2020
0
1
18519973.43
24246187.31
350734.00
3835586.00
8403994.00
17280397.00
82017514.00
▇▁▁▁▁
mort_cumulative_june30
0
1
16.37
21.29
0.51
3.20
5.89
17.51
82.19
▇▁▁▁▁
stringency_index_death_threshold
0
1
64.91
22.87
16.67
50.93
72.22
81.48
100.00
▂▂▂▇▃
The skim() output tells us how many cases (i.e., rows — which represent countries in this example) have missing data (n_missing). Notice that here is no missing data in this data frame. For each variable, it also gives the minimum (min) and maximum (max) values. For the character variables, this is the min and max number of characters in the names (which, to be honest, isn’t very useful). For the numeric variables, this is the min and max scores observed in the data frame (this is useful!). Also, for the numeric variables we get the mean, standard deviation, quartiles, and a mini histogram. Note that the final table is very wide, hover your cursor over the table and scroll over to the right to see the full output. We’ll learn more about these summary statistics later in the course.
Create a plot
The last section has a section header labeled: # Create a simple plot. In this code chunk a simple scatter plot using the ggplot() function is created. We’ll learn all about this function and how to create wonderful graphics in the Data Visualization Module. For now, just notice that the ggplot() function has many more arguments (the directions in the parentheses after the function name) than the others that we’ve seen — these arguments allow us to define how we want the plot to look.
df |>ggplot(mapping =aes(x = stringency_index_death_threshold, y = mort_cumulative_june30)) +geom_point(mapping =aes(size = population_2020)) +labs(title ="Early policy mitigation and cumulative mortality from COVID-19 in Europe",x ="Oxford Stringency Index when mortality threshold was reached",y ="Cumulative mortality through June 30, 2020",size ="Population")
Render your Quarto Analysis Notebook
Once we’ve completed our analysis, and ensured that each code chunk is running properly, we can render a report. Before doing so, please add your own name into the author: section of the YAML header — i.e., delete my name and put your name. Click the Render icon at the top of the RStudio window. This will create your report, which will automatically be saved in the same folder where the .qmd file is saved.
Note that when you render your report, the report pops up in your default web browser. Depending on the settings of your web browser, the pop up might be blocked, and you may need to make changes to your browser. Click here to allow pop ups in safari or here to allow pop ups in Chrome.
After the report pops up and you view it, be sure to close out the web browser tab where you’re viewing it so that when you modify your analysis notebook and click Render again, the opened report doesn’t interfere with allowing the new version to pop up. Occasionally, even when you do this, you’ll find that a new report doesn’t pop up the next time you Render. If this happens, click on the Background Jobs tab in the lower left quadrant of RStudio. To the right of that section, you may see the word Running, a Stop sign, and the a counter for how long the background job has been running. Click Stop, and the background job will end, and then you should be able to Render again without an issue.
Once rendered, you can export the .html output file of your results from RStudio Cloud and onto your computer. To do this, navigate to the .html file in the files tab (lower right quadrant of your RStudio session), once you find the 01-intro_to_R.html file, check the box to the left. Then, click on the More button (the blue gear), and choose Export. This will export the .html file from Posit Cloud to your computer. You can then drag it to your desktop or put it into a folder of your choosing on your hard drive. If you do this multiple times, note that your computer might start indexing the names: e.g., 01-intro_to_R.html (1). It’s bad practice to leave names like this. Once you drag the file to your desktop, rename the file and remove the space and (1), so that it’s called 01-intro_to_R.html.
In general, avoid naming files, or variables in files, with names that have spaces. For example, don’t give any type of data file (e.g., .Rds, excel file) or Quarto file a name that has spaces in it. For instance, use “mydata.Rds” — do not use “my data.Rds”. Likewise, do not put spaces in variables names — notice that in the example data frame we looked at in this Module, none of the variable names have spaces (e.g., country, country_code). I also advise that you do not name a data frame, or variables in a data frame, with a name that starts with a number. Naming your Quarto data analysis notebook (i.e., Quarto document) with a name that starts with a number is okay though (e.g., 01-intro_to_R.qmd).
One of the things I love about Quarto is that you can be creative and customize the look of your reports if you desire. There are many possibilities to try. We’ll explore all sorts of options later in the course. If you’re interested now, try changing the theme. Currently, I have the default theme called bootstrap set in the YAML header. Change the word bootstrap to minty — that’s a different theme. Render the report and see how the report changes. There are many nice themes built into Quarto — you can view them here. As another modification, try removing the toc: true line in the YAML header — just completely remove this line. Render the report again and you’ll see the table of contents disappear.
A Reproducible Workflow
As you begin working with data science tools, it’s important to establish a reproducible workflow. This refers to a set of clearly documented and repeatable steps in your analysis — allowing others (and your future self) to recreate your results. Reproducibility strengthens the reliability and transparency of your research, making your findings more trustworthy and easier to verify.
Artwork by @allison_horst
Here are a few key elements of a reproducible workflow to master:
File Organization: Start by adopting a tidy and logical file structure. Keep all your files well-organized and appropriately named, similar to the structure of the foundations project. Establish a reliable system for backing up your files. Down the road, you may consider incorporating a version control system like git into your workflow as you become more comfortable with these practices.
Data Management: Always use code to modify data frames. Avoid manually altering them, as this ensures you have a clear record of all modifications. For example, do not open a file in excel and make changes. Additionally, avoid overwriting the original data frame. As you progress with R, you may wish to divide the data folder in your R project into two subfolders, such as raw_data and clean_data. This separation allows you to preserve original data files in the raw_data folder and store the cleaned data, generated through your analysis notebook, in the clean_data folder.
Code Documentation and Organization: When building your analysis notebook, prioritize neatness, organization, and thorough documentation. Use comments generously to explain what your code does. In particular, write comments to outline your overall strategy and to document crucial discoveries as they arise. This information cannot be retrieved from the code alone, so documenting it as you go is essential. Make sure your code chunks follow a logical and sequential order. For instance, a code chunk that reads in a data frame should be placed before a chunk that uses it to create a plot. As you navigate your project, write and initially check your code chunks to verify they’re performing the intended tasks. Use the Run icon in RStudio to test individual lines of code or chunks. After all code chunks are written and checked, utilize the Restart R and Run All Chunks feature found under the Run icon. This function clears all objects in your environment, restarts R in the background, and runs the entire analysis notebook from top to bottom. This step is a robust way to ensure all parts run smoothly together, tasks are reproducible, and results remain consistent each time you return to your project.
Render your Output: Last, once everything is working as you like, you can Render your analysis notebook. To begin, we’ll render our outputs to html reports. But, later you may enjoy exploring other output options, including pdf, word, or powerpoint for example.
Remember, the goal is to create a workflow where your steps can be retraced from the raw data to the final analysis, enhancing transparency and reliability in your research. The video below walks through the steps of interacting with RStudio covered in this Module.
Important
Please complete these steps and then upload your rendered html report to Canvas as part of the Set Up RStudio Apply and Practice Activity in Assignments in our Canvas course. The video below demonstrates how to export the html file from Posit Cloud to your computer.
Writing Clean Code
In R, spacing, tabs, and line breaks (pressing Return or Enter) generally don’t affect how the code runs, but they do affect how easy it is to read. For example, whether you write:
mtcars |>filter(cyl==4)
or
mtcars |>filter(cyl ==4)
R will interpret it the same way.
💡 It’s often helpful to put each step in a pipeline on its own line, especially when using pipes (|>), to make the sequence of steps easier to follow.
You can also break long lines into multiple lines to keep your code tidy and avoid horizontal scrolling. Just be sure to keep complete expressions together. For instance, if you press Return in the middle of a function call and haven’t yet closed a parenthesis, bracket, or quotation mark, R will wait for you to finish. It shows a + prompt in the console — this is R’s way of saying: “I’m still waiting for the rest of the command.”
💡 If you get stuck at the + prompt, and aren’t sure how to finish, press the Escape key (in RStudio) to cancel the command and start fresh.
Why code style matters
While R is flexible about formatting, writing clean, readable code is a habit that pays off:
It helps you spot mistakes more easily.
It makes your code easier to revisit later — even weeks or months down the road.
It allows others — like instructors, collaborators, or future-you — to follow your logic without guessing.
💡 Additional clean code tips:
Use consistent spacing (e.g., always put spaces around = and comparison operators like ==).
filter(cyl ==4) # Goodfilter(cyl==4) # Harder to read`
Avoid copying and pasting the same code repeatedly. If you’re repeating yourself, consider writing a function (we’ll explore this later in the course).
Add comments inside code chunks using # to explain why you’re doing something, not just what you’re doing. When you use a single hash symbol inside a code chunk, the text following the hash symbol serves as a comment and will not be evaluated by R. In this way, you can write helpful notes to yourself about the code you have written. This is a wonderful habit to adopt. Write notes to your collaborators — or to your future self. Others (and future you) will be thankful when trying to figure out why you did what you did down the road.
# Filter to include only 4-cylinder carsmtcars |>filter(cyl ==4)
Use informative names for your variables (e.g., cyl, short for cylinder, instead of x).
💡 There are even style guides (like the tidyverse style guide) that provide more guidance as your projects grow.
Alternative Coding with the Pipe
In this course, I will be consistent with feeding a data frame into a pipe. But there is an alternative way that the code can be written. I’d like to show you this alternative as you will see it from time to time in other resources. In the code chunk below I show two ways of using glimpse(). First, is the initial way that I showed you, the second is an alternative way in which the data frame is the first argument to glimpse().
Most functions that we’ll explore in this course can work with either approach.
Learning Check
After completing this Module, you should be able to answer the following questions:
What is the Posit Cloud, and why are we using it instead of installing R and RStudio locally?
How do you create and render a Quarto notebook, and what elements must it contain?
What is the purpose of code chunks, and how do you run them?
What are R functions, and how do you use packages like skimr, here, and tidyverse?
How do you use the pipe operator (|>) to streamline code?
What does the glimpse() function show you about a data frame?
How do you import a data file using read_rds() and here()?
What are key features of a reproducible workflow in RStudio?
Why is it important to write clean, readable code, and what strategies help with this?
Resources
Learning R takes time. In large part, it’s about being conscientious and thoughtful. Practicing a bit everyday (or most days at least) is the key to success. There are many wonderful resources to help you on your journey. Learning how to tap into these resources is a very important first step.
Artwork by @allison_horst
Here are a few of my favorite free online resources:
Drs. Hadley Wickham, Mine Çetinkaya-Rundel, Garrett Grolemund’s R for Data Science
That concludes the Intro to the Tools Module. Congratulations for completing your first Module. I hope that you have learned a bit about R, RStudio, and Quarto and are excited about what is to come in the remainder of the course!
Credits
This Module drew from the excellent descriptions of R, RStudio, and data science with R by Drs. Hadley Wickham, Mine Çetinkaya-Rundel, Garrett Grolemund in their book entitled Data Science with R, 2nd Edition.
Footnotes
A shell is a way for you to interact with your computer’s operating system by typing commands. It’s like a text-only version of clicking on icons or using menus in a graphical user interface.↩︎
The YAML header is where much of the report styling and customization happens. As you grow your Quarto skills, you may want to begin adding to the YAML. If interested, check out some tips for creating the YAML.↩︎
The double colon operator (::) in R programming is a valuable tool for specific use cases. Here are several reasons why it’s particularly useful:
Namespace clarity: When you use the double colon operator, it’s immediately clear which package the function belongs to. This is especially helpful in situations where multiple packages might contain functions of the same name. By using pkg::fnct(), you avoid ambiguity and ensure that the correct function is called.
Avoiding conflicts: Sometimes, loading multiple libraries can lead to name conflicts, where different packages have functions with the same name. By using the double colon operator, you sidestep these conflicts because you specify exactly which package to use each time you call a function.
Memory management: Loading a full package with the library() function can consume more memory because it makes all functions and data within the package available in your R session. If you’re only using one or two functions from a package, it’s more efficient to call them directly with the double colon operator. This way, you’re not loading unnecessary functions into memory.
Script transparency: When sharing scripts with others or running code after a long time, the use of the double colon operator makes the script more self-contained and understandable. There’s no need to look elsewhere in the script to find out if a specific package was loaded with library(). This can make collaboration and troubleshooting easier.
It doesn’t matter whether you’re on a Mac (Cmd + Enter) or a Windows/Linux machine (Ctrl + Enter), the functionality remains the same.↩︎
In R, a vector is a one-dimensional data structure that can hold elements of the same data type. It is a fundamental data type in R and is used to store and manipulate collections of values. For example, a set of numbers is a vector.↩︎
A matrix is a two-dimensional data structure consisting of rows and columns. It is a rectangular arrangement of numbers, symbols, or expressions organized in rows and columns.↩︎
In R, a list is a flexible data structure that can hold elements of different types, such as vectors, matrices, data frames, and even other lists. It is a collection of objects grouped together into a single entity.↩︎
In a file system, the root directory refers to the top-level directory or the starting point of the directory hierarchy. It is denoted by a forward slash (“/”) in Unix-like systems (e.g., Linux, macOS) and by a drive letter followed by a colon (e.g., “C:”) in Windows systems. The root directory serves as the parent or base directory for all other directories and files within the file system. It contains the highest level of organization and provides the foundation for the entire directory structure.↩︎
For those interested, double is the default data type for numeric values in R and is also known as a double precision floating-point number. The term “double” comes from the fact that the data type typically uses double precision, which means it can store numbers with a higher level of precision compared to single precision (float) numbers.↩︎
For those curious, factors are often created from character vectors or numeric vectors that represent categories or groups. By converting these vectors into factors, R assigns a unique integer value to each distinct category and stores the corresponding labels or levels. This integer representation enables efficient storage and manipulation of categorical data. Factors have two main components: the levels and the labels. The levels represent the distinct categories or groups, while the labels correspond to the actual values or observations assigned to those categories. The levels are stored internally as integers, and the labels are stored as character strings.↩︎